
Large service desks are flooded with hundreds of IT support issues a day. And because no two issues have exactly the same wording, service desks must manually resolve each one — from resetting passwords to provisioning software to answering questions about policy.
New employees, for instance, inevitably encounter a number of IT issues during onboarding, such as: “Hi! I joined the marketing team two days ago and I just realized I don’t have a Zoom Pro license. I’m sure you get a ton of these requests, but I’d really appreciate help as soon as possible. Thanks!” At most companies, this kind of issue requires the attention of service desk agents, who read through a long and complex description to find what is often a simple fix.
In fact, under the surface, one-of-a-kind support requests describe surprisingly similar problems. The rise of SaaS applications in particular — Zoom, Salesforce, Office 365 — is driving homogeneity across companies and industries, which means that just a handful of automated workflows can resolve thousands of issues on the back end. Ultimately, the challenge for us at Moveworks is to understand the unique ways that employees talk about these same issues.
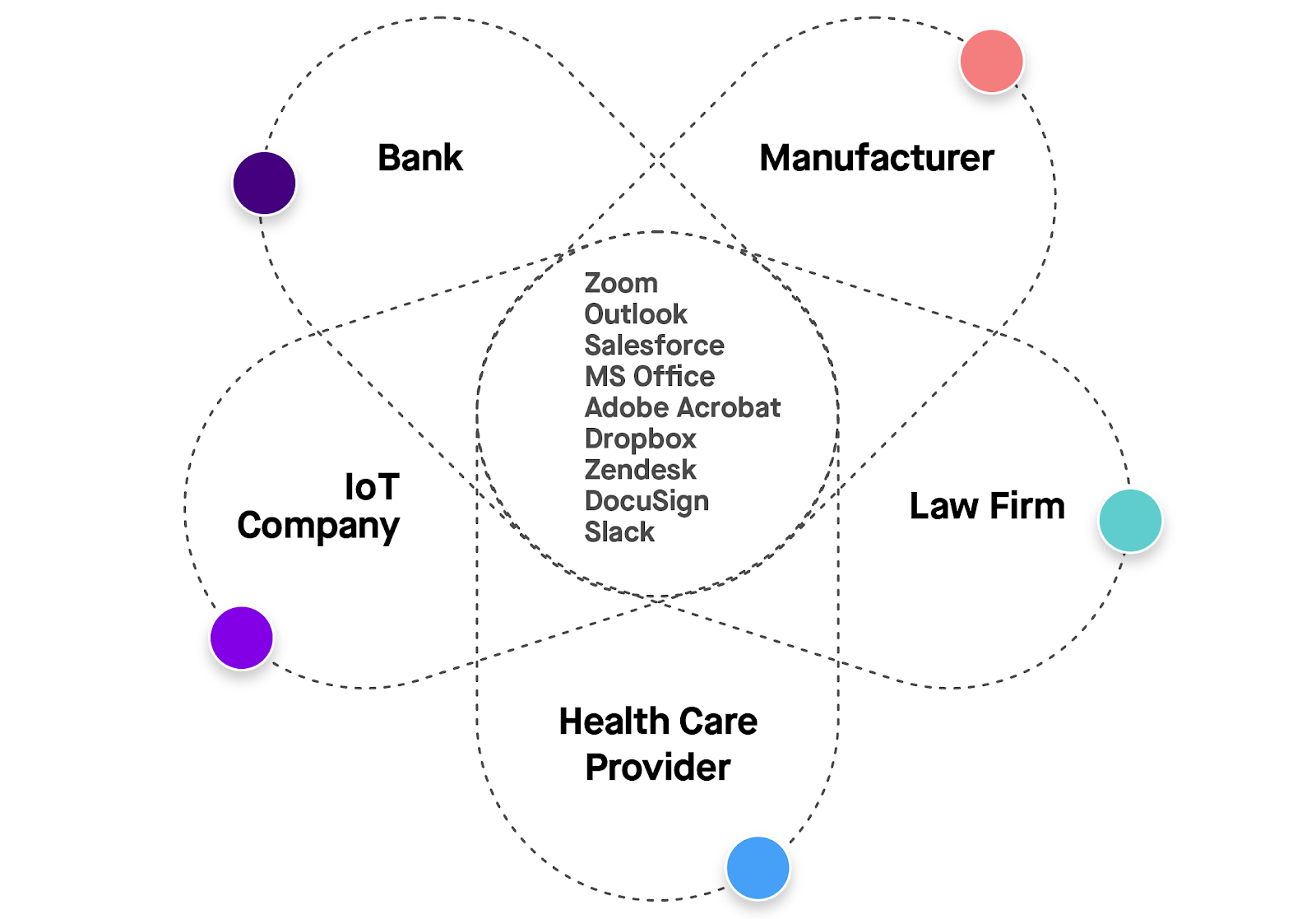 Figure 1: While every company is unquestionably unique, many use the same IT to conduct business.
Figure 1: While every company is unquestionably unique, many use the same IT to conduct business.
One of the critical techniques we use to understand these support tickets is Collective Learning. At Moveworks, we benefit from analyzing over 75 million IT issues, and by analyzing what they have in common, our machine learning models can understand the language employees use to explain their IT problems. In this blog, we'll cover:
- The techniques behind Collective Learning
- How Collective Learning breaks down complex IT issues
- The impact of Collective Learning for both service desks and employees
Uncovering the structure of IT issues
The idea behind Collective Learning is simple: strength in numbers. What we realized was that — as a third party — Moveworks could aggregate data from dozens of different companies to gain universal insights about seemingly unique IT issues.
Behind the scenes, Collective Learning requires pooling anonymized data from as many sources as possible. Anonymization has two major benefits: first, protecting internal data; and second, allowing our models to identify linguistic patterns under the surface.
After we anonymize data, the next step is normalization, which throws these patterns into sharp relief. Simply put, normalization means transforming language into a generic form in order to highlight common characteristics. Consider Figure 2. “Mark” and “sales email list” are specific nouns, but, these entities can be considered in broader, more universal categories, like $PERSON or $GROUP. By generalizing these entities, a model receives a large input of training data relevant to the IT world and applicable across many companies and industries.
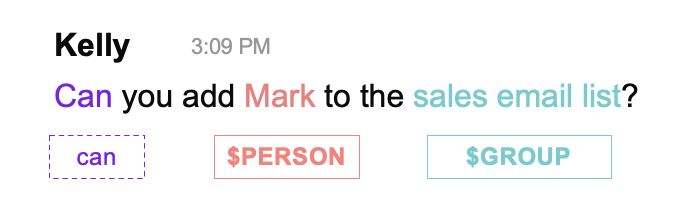 Figure 2: By normalizing data, specific entities become generic entities, which can be used to train machine learning systems.
Figure 2: By normalizing data, specific entities become generic entities, which can be used to train machine learning systems.
Collective Learning in action
So what does Collective Learning look like in a live environment?
Let’s explore Figure 3: three different questions from three different organizations in three different industries. Attempting to train a machine learning system on these specific issues at each company will result in poor performance because there are simply not enough examples.
However, Collective Learning gives us an opportunity to use machine learning to solve all of these issues. Through normalization, we can apply the same name — video conferencing application — to entities like Zoom, Webex, and Google Hangouts:
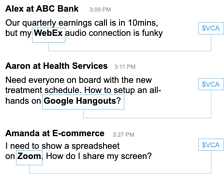 Figure 3: Collective Learning takes advantage of common IT entities, like video conferencing application, to automatically resolve issues.
Figure 3: Collective Learning takes advantage of common IT entities, like video conferencing application, to automatically resolve issues.
And Collective Learning can go even further, normalizing entire sentences to learn the underlying logic of language. Here in Figure 4, at first glance, these look like completely different IT issues that would require the service desk to address manually. But, considering “Zoom” and “Confluence” and “Trello” all as $SOFTWARE makes it easier for the model to pinpoint patterns in how people ask for support.
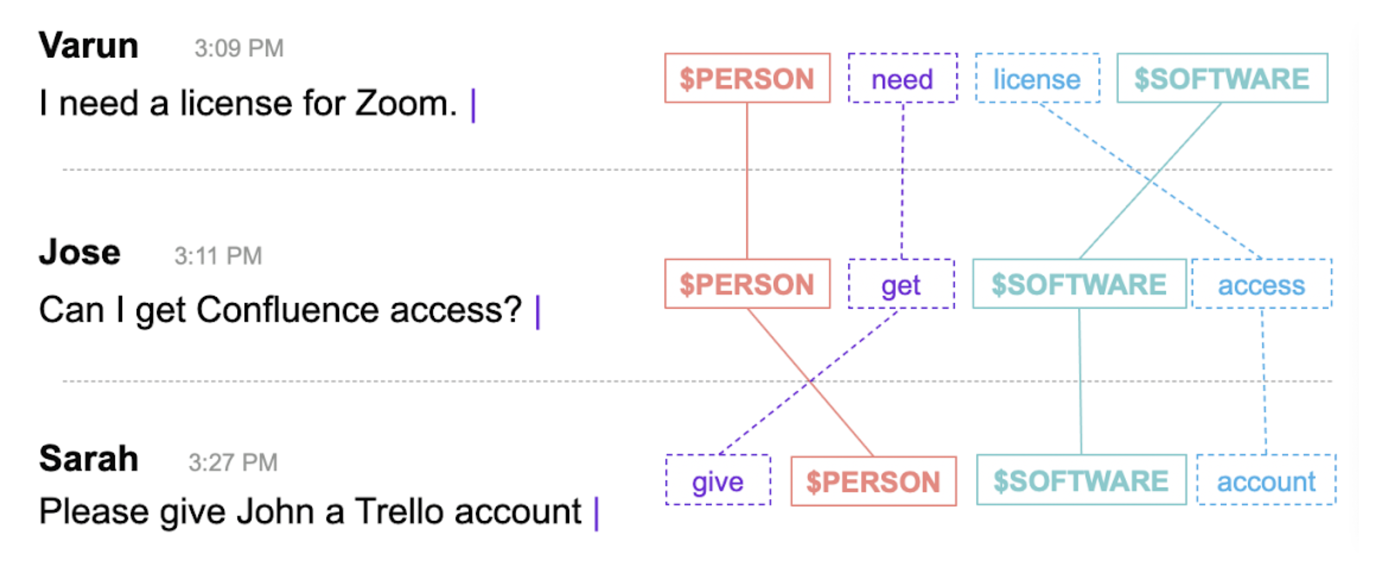 Figure 4: Collective Learning applies this logic of normalizing entities to entire sentences, illuminating patterns across companies and industries.
Figure 4: Collective Learning applies this logic of normalizing entities to entire sentences, illuminating patterns across companies and industries.
Despite starting with only a couple of examples, generalizing language patterns allows us to generate many alternate combinations. That way, our machine learning models already recognize the structure of future issues — even if they look different from the original examples.
 Figure 5: Learning language patterns lets us generate similar utterances from a few examples.
Figure 5: Learning language patterns lets us generate similar utterances from a few examples.
The power of the collective
In the past, machine learning has been the exclusive domain of large enterprises, which have access to larger data sets. The power of Collective Learning lies in allowing smaller companies to reap the benefits of machine learning — by transforming a couple of examples into millions of data points.
In fact, when Moveworks onboards a new organization to our platform, Collective Learning allows us to recognize an ever-increasing percentage of relevant entities, on day one. Now, this network effect means our bot can make sense of 99.9% of IT entities, without additional training.
 Figure 6: As our customer base grows and we continue to collect IT ticket data, Moveworks’ ability to recognize entities increases exponentially.
Figure 6: As our customer base grows and we continue to collect IT ticket data, Moveworks’ ability to recognize entities increases exponentially.
Thanks to Collective Learning, Moveworks immediately understands our customers’ IT environments, regardless of their size or industry. Every company has its own support challenges, of course, but understanding the language of IT issues shouldn’t be one of them. The trick is capturing the right information, giving machine learning models the data needed to make accurate predictions about what employees need. For Moveworks, that trick is Collective Learning.
Contact Moveworks to learn how AI can supercharge your workforce productivity.
Table of contents


