
Table of contents
Why is understanding natural language a hard problem?
The ability to string a few words together to convey ideas is central to what makes humanity unique. In fact, our civilization wouldn't exist without natural language. For about 100,000 years, it has remained central to how we communicate our ideas and coordinate our actions. It’s part of what makes us human.
However, we don't use words alone to express ideas, and they are never expressed in isolation. Time, place, our environment — these are all important signals we use to interpret the true meaning behind language. Furthermore, words and sentences are often inherently ambiguous, which is why we use conversation to more fully understand each other.
This is why it is incredibly hard for machines to understand natural language. Language is complex, nuanced and can shift its meaning in different contexts. In short, language is:
- Inherently ambiguous
- Vast, versatile, and colloquial
- Dynamic
- Contextual
- Better understood with conversation context
This presents some interesting challenges when building a machine learning powered Natural Language Understanding (NLU) system.
Language is ambiguous
A single word can have many possible meanings. At work, someone might try to add me to an email distribution list (DL), spelling my name correctly and providing what he thinks is the DL name, and still, ambiguity will remain.
People are great at describing what they see, but not so good at saying things in a way that will help the listener understand quickly. In the IT ticketing world we focus on, we see this happen when employees file tickets that usually describe symptoms and only rarely describe the underlying issue in the way an IT specialist would phrase it.
 The way someone describes an issue rarely matches the title of the corresponding article
The way someone describes an issue rarely matches the title of the corresponding article
As mentioned in the last blog, a good service desk agent draws on experience to grasp what the employee is talking about, but for a natural language understanding (NLU) system, this isn't so easy. Scripted rules are impractical. It would take hundreds of rules, for example, to match all the ways people ask to add a colleague to a list. An NLU system needs to operate more like a service desk agent, by ignoring irrelevant words (what we call “noise”), recognizing what entities the person is talking about, and identifying the person’s intent.
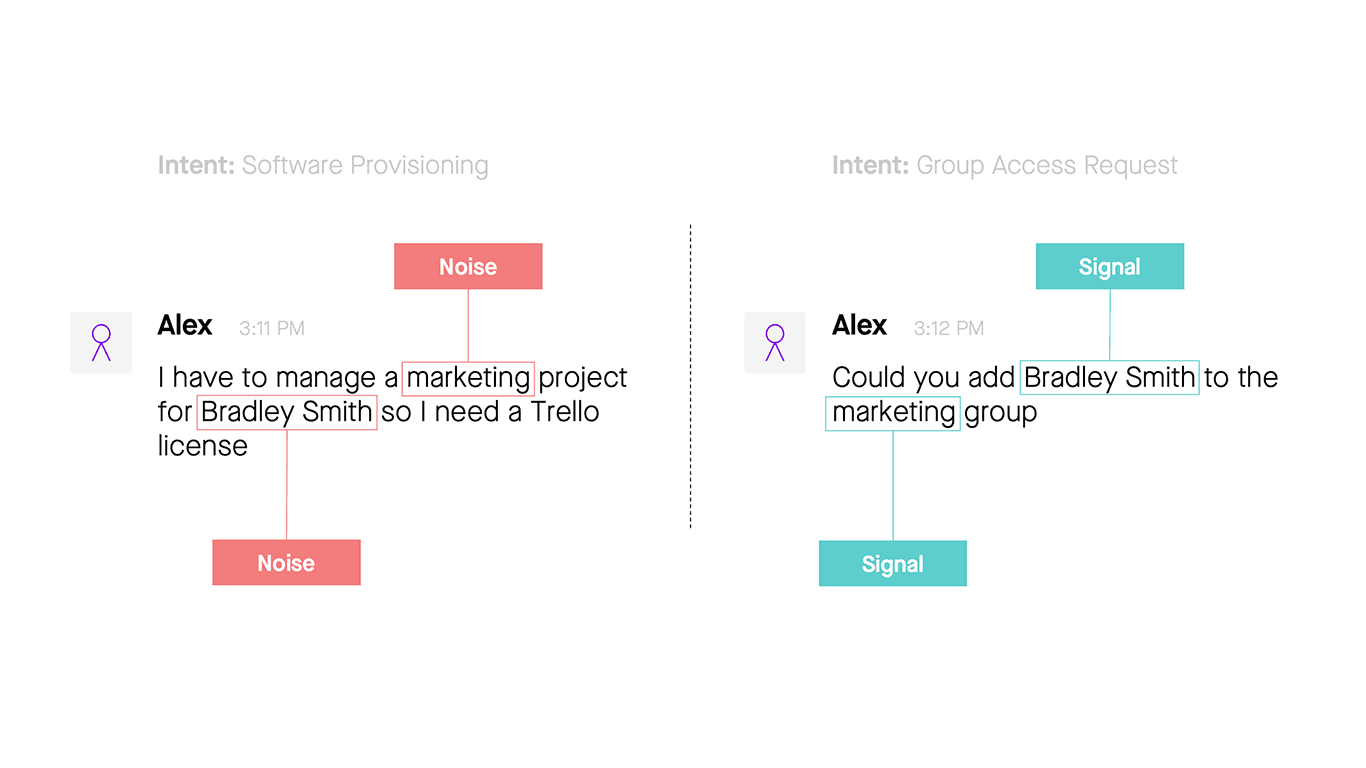 Not every word in a request is important; NLU systems must detect the words that matter
Not every word in a request is important; NLU systems must detect the words that matter
Language is vast, versatile, and colloquial
Language is vast, and you’re only scratching the surface by counting the 600,000 entries in the Oxford English Dictionary. Words can be assembled in many different ways, making it hard to predict which combination of words a person will put together to describe an issue.
 Keyword-based search struggles with the different meanings words take on, in context
Keyword-based search struggles with the different meanings words take on, in context
Our brains are built to handle the vast variety of words, quickly associating each word we read or hear with its probable meaning. If you hear the words “bank”, you can associate it with a few different meanings — a river bank, a bank where your deposit your salary, to “bank on” a person, and so on. To disambiguate the meaning, your brain quickly looks at the context of the word in the sentence, as well as the relation of the sentence to the overall context of what you’re doing and talking about.
Now consider an NLU system that tries to find the meanings of words quickly. A hard-coded approach is slow, since it needs to test each word it reads against a list of words, looking for a match. A faster approach is to look for common patterns in what people say, and learn which words are likely to appear where in the pattern. IT requests have common patterns that can be understood with machine learning models that take sentence semantics into account. When we know the pattern, we know which word is likely to be someone’s name, and which is likely to be the name of a software package — even without looking up a dictionary.
Language is dynamic
New words appear frequently, and expressions change often. Unless you plan to hire an army of people to analyze and accommodate new expressions, you'll need a system that trains and re-trains its language understanding on its own. We’re already seeing consumer-facing systems that learn constantly, like the auto-completion for web search queries.
An NLU system is more powerful in a focused setting like IT, where it can focus on the language patterns employees use there. But there’s a downside to machine learning in enterprise IT environments: not enough data. Machine learning requires huge amounts of data to deliver precise results. To learn, an enterprise NLU system needs creative approaches to finding enough data — or augmenting the data it has.
Language is contextual
No one likes to waste their time explaining — or listening to — every little detail, so language is built to convey ideas in a few words. We do this by being aware of context. When a colleague approaches me with a question, I count on my memory and senses for context: Who is she? What topics have we discussed recently? What’s her team working on now?
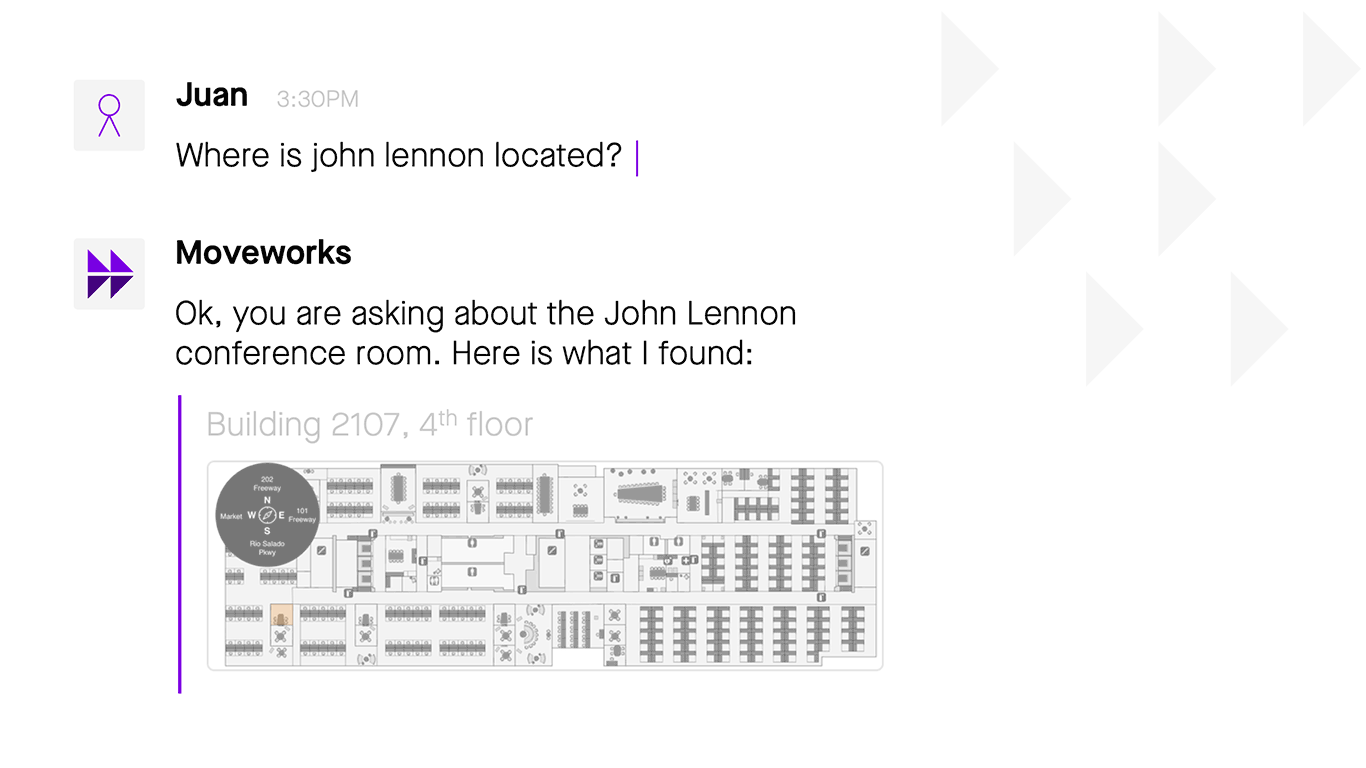 A good NLU system uses context to clarify ambiguous questions and statements
A good NLU system uses context to clarify ambiguous questions and statements
As people trained on years of having conversations, we draw on our senses and memory to get context effortlessly. When we try to create an NLU system to do this, we see it’s not effortless. Contextual cues that a person would pick up are not available to the NLU, unless we build a way to supply information like time, identity, and location.
Language is conversational
When we send a message to someone, we usually type just a few words because we know we can fall back on conversation to clear things up. If our friend wants more detail, she’ll just ask for it, conversationally.
It turns out, basic conversational ability is hard to build in an NLU system. Think about our expectations when we chat with a friend. We’re thrown off if a reply strays from the thread, we hate to repeat what we’ve said, and we want just enough information in each reply. Too much, and we feel man-splained; too little, and we feel ignored.
To build an NLU system that gives people a natural flow of conversation, we need a probabilistic approach. When talking with a friend, you’re never 100% certain what sort of response your friend is waiting for, so you choose the words you think are most likely to get your point across, right now. Machine learning-based systems are well suited to probabilistic problems like this. If a machine learning model has been trained on enough relevant data, it can accurately predict the right response in a situation.
In an upcoming post, we’ll dive into useful techniques that can address this and the other hard problems that stand in the way of building a good NLU system.


