
Table of contents
The world is getting smaller — and that means trouble for IT teams.
Increasingly, companies are depending on international employees to meet their goals. And while access to a global talent pool has many benefits, it can be a real challenge for the teams tasked with supporting a global — and multilingual — workforce.
The most common approach to this challenge? Hiring professionals who specialize in various languages. But as companies strive to do more with less in today’s economy, hiring and managing an expensive army of agents is far from an attractive proposition.
Another option is to deploy a conventional support chatbot. Again, this is not a cost-efficient solution. Your team has to identify every single way an employee could ask for help, train — and re-train — a generalized translation model, manually script out dozens of conversations, and then translate every resource in your knowledge base. All of that work draws on IT’s already limited resources.
In short, the usual multilingual support methods are not scalable.
We decided to find a new way — and I’m proud to say our investment paid off: Moveworks is now capable of supporting employees in over one hundred languages.
How, you ask? Well, we understand that engaging people in their preferred language is deceptively difficult. It’s not just translation. Today, I’m going to dig into the details, explaining the four common technical problems that trip up conventional chatbots and how we’ve tackled them.
Problem: Typical language models don’t account for domain- or culture-specific language.
The same word has different connotations based on context. And the standard translation tools that traditional chatbots use are not equipped to handle these nuances.
Common language models are trained using domain-agnostic data like e-news, articles, books, and other information scraped on the web. A consequence of using off-the-shelf models is that the bot will not know when to move towards enterprise term translations versus everyday terms and vice versa. The result is a failed employee interaction.
For example, if you type casque into a standard translation tool, it will state that casque means helmet. However, if a person refers to casque in an IT context, they would actually be referencing a headset. You can see where translations can get tricky.
Solution: Models trained on enterprise support language, supported by annotation
Moveworks’ language models are trained using a proprietary enterprise support data set, from 400 million examples from utterances and support tickets. That information is further enriched by 20 billion lines of open-domain data from support websites like Stack Overflow and Microsoft.
Another key component of accurate language models is an annotation team that can further disambiguate when a word has multiple meanings. Moveworks employs a team of linguists trained on domain-specific terms and tasks for different languages.
Data annotation ensures high-quality training data and, consequently, the accuracy of our machine learning models. In the case of multilingual enterprise support, data annotation is vital: there are simply too many nuances and variances to be captured just by machine learning algorithms. Before deploying a new model, our team confirms or changes language determination, domain annotation, and intent-entity predictions. The result is a market-best, optimized language model.
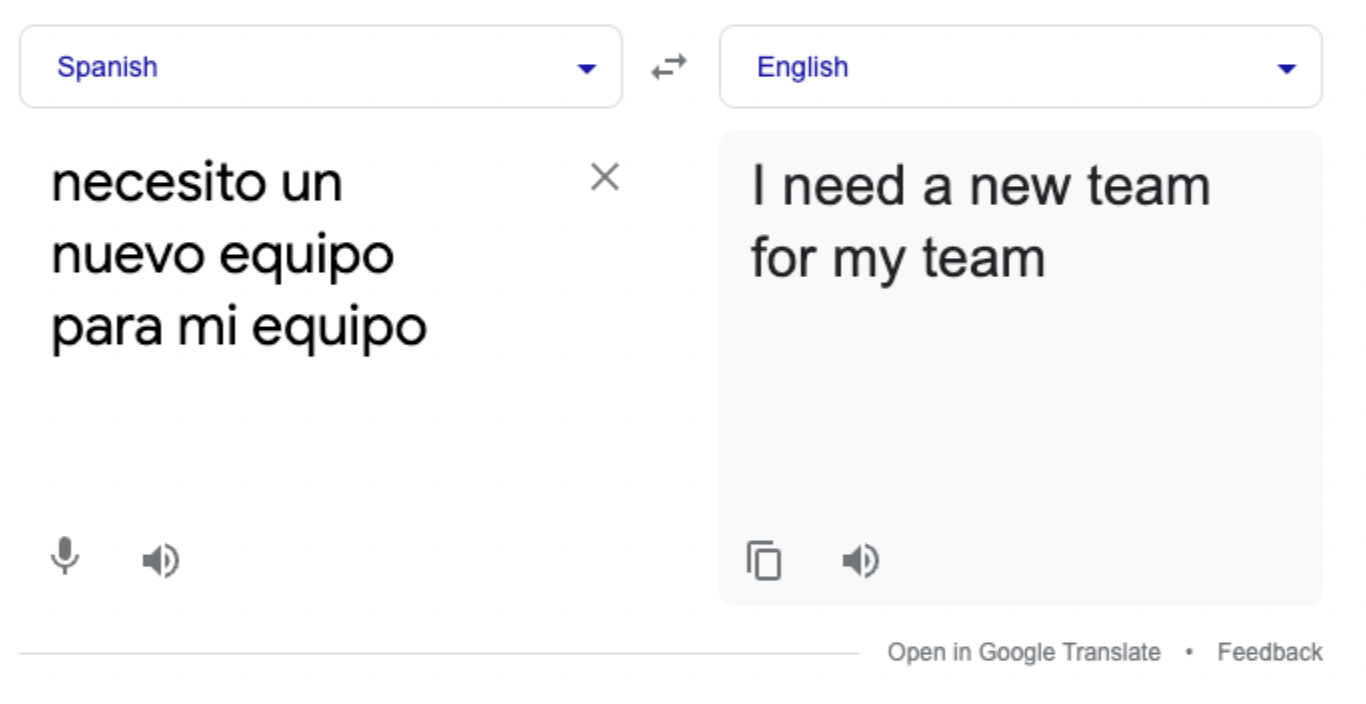 Figure 1:“Necesito un nuevo equipo para mi equipo” means “I need a new computer for my team.” Google incorrectly translates the statement since it’s not trained on enterprise data. This is just one example of how generalized language models can be wrong.
Figure 1:“Necesito un nuevo equipo para mi equipo” means “I need a new computer for my team.” Google incorrectly translates the statement since it’s not trained on enterprise data. This is just one example of how generalized language models can be wrong.
Problem: There is no limit to the ways employees ask for help.
Existing chatbots are deterministic, relying heavily on rigid dialogue flows that provide pre-determined “conversational” paths the user can go down.
Scripting out and maintaining independent decision trees in one language is hard enough. in fact, we've found that there are around 500,000 different use cases in practice today across our customer base.
Now imagine doing so for just one more language. That's hours wasted on anticipating phrases and keywords that follow unique semantic rules. That's hundreds of thousands of dollars wasted on finding someone who can build a comprehensive, native understanding of multiple langauges.
At best, managing multilingual dialogue flows is not scalable. At worst, it’s impossible.
Solution: Language Core, an ensemble of NLU models working in unison
Moveworks understands millions of possible utterance permutations, regardless of language. Every utterance goes through more than ten models that correct spelling, attribute parts of speech, identify entities, and more to understand a sentence without any hardwiring. At Moveworks, we call this process Language Core™, one part of our Moveworks Intelligence Engine™. Moreover, we aggregate data across all customers to dramatically increase prediction accuracy.
Before going through the Language Core™, the bot conducts on-the-fly translations to English using an open-source language model that’s fine-tuned through our proprietary enterprise data set. When the bot dynamically decides on the best response, we translate it back into the language of the utterance for the employee. Our approach ensures we can add languages quickly and that all languages benefit from all technical advancements in machine learning and artificial intelligence.
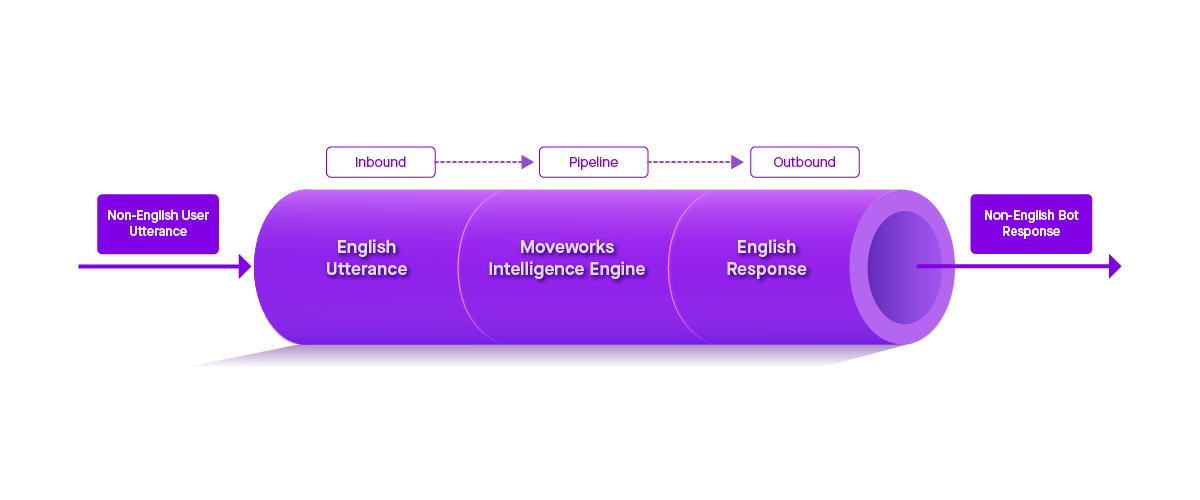 Figure 2: How Moveworks translates non-English user utterances.
Figure 2: How Moveworks translates non-English user utterances.
Problem: Knowing what to translate — and what to not translate
When do you translate words, and when do you not? In an enterprise setting, there may be terms that are only used in the primary language.
Let’s look at a simple example. A Spanish speaker may ask for access as so: “Necesito agregar Ahmed a la lista de distribución de Sales.” Here, an employee is asking in Spanish to add a person to a specific group that is in English, “Sales”. If a bot can’t handle the translation of two languages simultaneously, the bot’s response will be unsatisfactory, or flat-out wrong.
Solution: Preemptively tagging entities with multilingual named entity recognition
Moveworks' models leverage multilingual named entity recognition. We preemptively tag entities — the modifier the customer uses to describe their issue — and preserve them during the transformation process. Our bot is then able to use the original English entity to ensure accurate results.
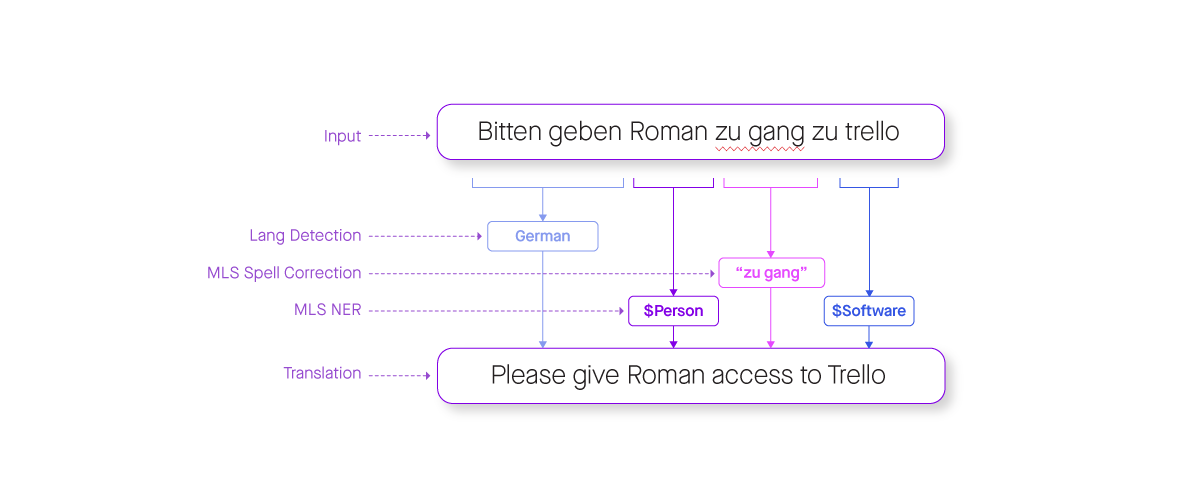 Figure 3: Here is an example of Moveworks' multilingual support named entity recognition. “Roman” and “Trello” are identified as entities and are not translated.
Figure 3: Here is an example of Moveworks' multilingual support named entity recognition. “Roman” and “Trello” are identified as entities and are not translated.
Problem: Translating resources and communications for the user
When using traditional chatbots, businesses must pre-emptively translate resources in their backend systems and portals. Not only must businesses aggregate the right body of resources to be translated, they must also run each resource through a language model (or outsource to 3rd party translation teams) and then create and manage a governance structure for review. Every time a knowledge base article changes, internal teams must go to each translated version and update: it’s a daunting task.
Solution: On-the-fly translation of knowledge, comms, and more
Moveworks leverages our multilingual support models to translate relevant snippets of knowledge base articles on-the-fly, so you do not need to create a dozen different translated iterations.
We also automatically translate non-English tickets from emails or self-service portals for English-speaking service desks. An employee can draft tickets in their native language and choose to send a translation, Moveworks will create a ticket in English using machine translation, and the agent’s response will be fully translated back into the user’s preferred language. In short, Moveworks supports bi-directional translated communications.
Additionally, Moveworks enables multilingual campaign communications. An internal service desk can send a mass email, and Moveworks will automatically translate it to the user’s preferred language. If the language detected in the comms message equals the user’s preferred language, no action will be taken.
The speed of our translations is powered by our expertly designed machine learning infrastructure, which minimizes the memory footprint of computations while minimizing latency. Moreover, translation quality is not compromised, no matter the message’s length. This is all done without any lift or additional resources from you.
My team and I understand the pain of trying to support a multilingual workforce. Going into this project, we knew it wasn’t going to be easy to build a solution that enables users across the globe to use their language of choice.
But that’s exactly why we’ve invested so much time and energy in our multilingual platform. We want to positively impact businesses across the world by making it easier for them to support their employees in any language..
To do that — we had to deeply understand where typical chat-based solutions break down. We had to find a way to manage the huge logistical challenges waiting behind a seemingly simple conversational interface. And we had to build technology that goes far beyond the limitations of earlier conversational platforms. Now, we’ve made it possible to deliver near-native employee service in more than one hundred languages.
With Moveworks, a company like Albemarle based in the US, but with operations in Asia, South America, and Oceania, can meet employees on their terms, in a cost-effective way that doesn’t also discount experience.
There is rarely a silver bullet. A lot of work has gone into our multilingual platform. I’m proud of what we accomplished here, and I’m excited to continue striving toward a world where no employee is held back from focusing on the work that matters.
Reach out to schedule a demo and see how you can scale support to 100+ languages.


