
Table of contents
Waiting for an important IT issue to be resolved is frustrating. Fortunately, for many common issues, the IT team can all but eliminate that delay by providing automatic resolution, powered by artificial intelligence. We’ve already seen on this blog how AI tackles tickets that once took three days to remediate and handles them from start to finish in under a minute.
Of course, there will always be some issues that require human intervention — AI software can’t replace the toner in your printer, for instance. In these cases, it’s critical to get the right subject matter experts involved as quickly as possible. The trouble is, for most service desk teams, assigning tickets to the correct resolver group is complex, slow, and prone to human error.
It takes an average of five hours, in fact, before an IT service desk agent first looks at an employee-submitted IT ticket, based on Moveworks’ analysis of millions of such tickets across dozens of organizations. For most of that time, the ticket is simply sitting in a queue in an IT service desk system, waiting for someone to review it and then either act on it or route it to a different team. In an era when business travel, conference rooms, and even catered lunches can be reserved in a matter of moments, urgent IT issues still spend hours or days before the remediation process even begins.
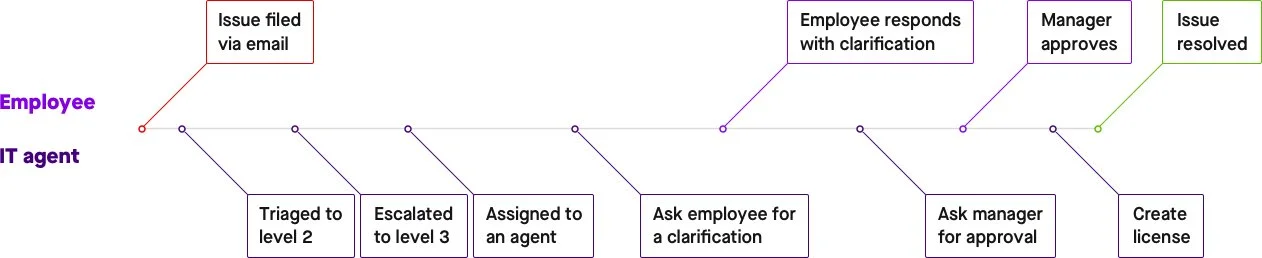 Figure 1: IT tickets can take days to reach the right hands with the proper context — all before resolution gets underway.
Figure 1: IT tickets can take days to reach the right hands with the proper context — all before resolution gets underway.
In Part 1 of this two-part series, I’ll explore the many obstacles that have hindered efficient ticket routing in the past, from insufficient contextual knowledge to the challenge of small datasets. Next week in Part 2, I’ll then explain how Moveworks uses machine learning (ML) to overcome these obstacles and route tickets to the best “assignment group” in seconds, including in organizations with hundreds of assignment groups that are each responsible for a specific type of issue. But first, we need to understand the problem:
How service desk teams manually resolve IT tickets
IT support organizations typically organize themselves into a three-tiered support model:
- Level-1 (L1): Personnel who possess broad — but not deep — technical knowledge. They solve common support issues for which there are known solutions or workarounds.
- Level-2 (L2): Technical support specialists who are experts in specific products or services. They have deep knowledge within their discrete area of expertise.
- Level-3 (L3): Engineers, architects, or product experts, called in to resolve issues only in exceptional circumstances when all other options have been exhausted.
When you file an IT ticket for an issue — such as “Help, I forgot my password!” — the L1 frontline agents are usually first on the case. For something simple like a password reset, these L1 agents can resolve the issue pretty quickly themselves once they get to it, as they have the means to either reset the password or to direct the user to the relevant page on a self-service portal. This means that delays for routine IT issues are a product of the limited capacity and availability of the L1 team.
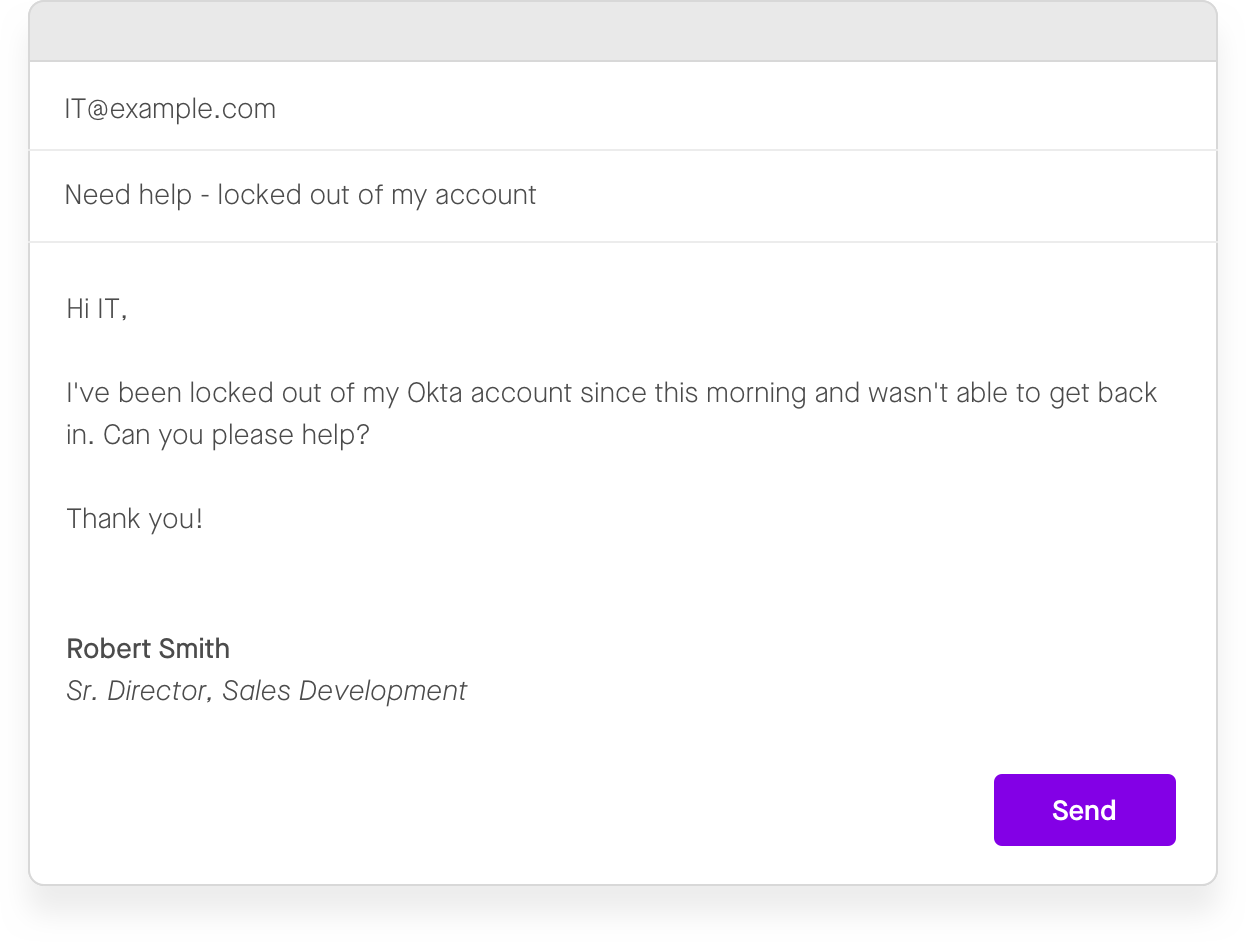 Figure 2: Common IT tickets like this one are easy to fix — but still can spend hours in the queue.
Figure 2: Common IT tickets like this one are easy to fix — but still can spend hours in the queue.
More complex issues to troubleshoot, like “I lost access to a database on an internal server,” cannot be resolved by the L1 team — they require a technical support specialist. So when this variety of ticket appears in their queue, L1 agents read the ticket content and must then assign it to an L2 support team. But with dozens or even hundreds of available support groups to choose from, it isn’t hard to see why L1 agents frequently assign the ticket to the wrong L2 team.
At this point, tickets can fall victim to what’s known as the “ping-pong effect” — getting assigned back and forth between the L1 service desk and different support teams until finally reaching the right one. Each ticket reassignment can add hours to the life of a ticket. And needless to say, this effect is a headache for everyone involved: employees wait in the dark for their ticket to be assigned, support teams deflect away misrouted tickets, and IT leadership fields complaints from both groups.
Different organizations face different challenges
Using this conventional system, organizations have to strike a difficult balance. On one hand, it’s useful to have lots of very precise assignment groups so that tickets get to the subject matter expert faster. On the other hand, with too many assignment groups, service desk agents struggle to identify the right group — usually from a picklist in the service desk software — for a given ticket. Faced with this long list, agents tend to use the few assignment groups they’re most familiar with, which, in turn, forces a second agent to do another round of triage to remedy the error.
In an attempt to avoid these complications, some companies have outsourced their L1 and L2 service desks to a managed service provider (MSP). According to a 2017 survey by Harvey Nash and KPMG, 32% of companies now use an MSP for their service desks, enabling them, at least in theory, to focus their efforts on core business initiatives rather than on IT issues. But while MSPs offer an alternative business and organizational model for IT support, they don’t address the functional difficulties of ticket routing. The core predicament still exists: no human can accurately remember the responsibilities of each assignment group when there are 50 or more to choose from — even within specialized IT support companies like MSPs.
 Figure 3: Routing a ticket to one of 50 or more assignment groups is a challenge for human agents.
Figure 3: Routing a ticket to one of 50 or more assignment groups is a challenge for human agents.
This type of problem — one involving hard-to-remember values, large volumes of relatively similar inputs, and often significant time pressure — is tailor-made for machine learning. As we’ll see in the following sections, however, applying ML to an individual organization’s IT support infrastructure is a daunting task.
The pitfalls of classical machine learning models
The job of a machine learning system is to learn from past data to generate predictive models, also known as ML models, that will inform the system’s decisions. In the case of IT ticket triage, the predictive model reads various fields of a ticket to predict what the assignment group value (and other ticket fields, if desired) should be.
Classical machine learning models that tried to predict these values learned only from the short description — essentially the subject line of the ticket — and one or two other, hand-picked fields. By consuming just a few input values, which are called “features” in the ML community, learning algorithms missed out on a mountain of useful data. And because classical learning required the IT team to choose those few features in advance, it forced them to ignore fields that could have ultimately provided the best basis for making triage predictions. By contrast, the latest approaches to machine learning can consider all fields of a ticket and mathematically determine which are most predictive — but we’ll save that discussion for Part 2.
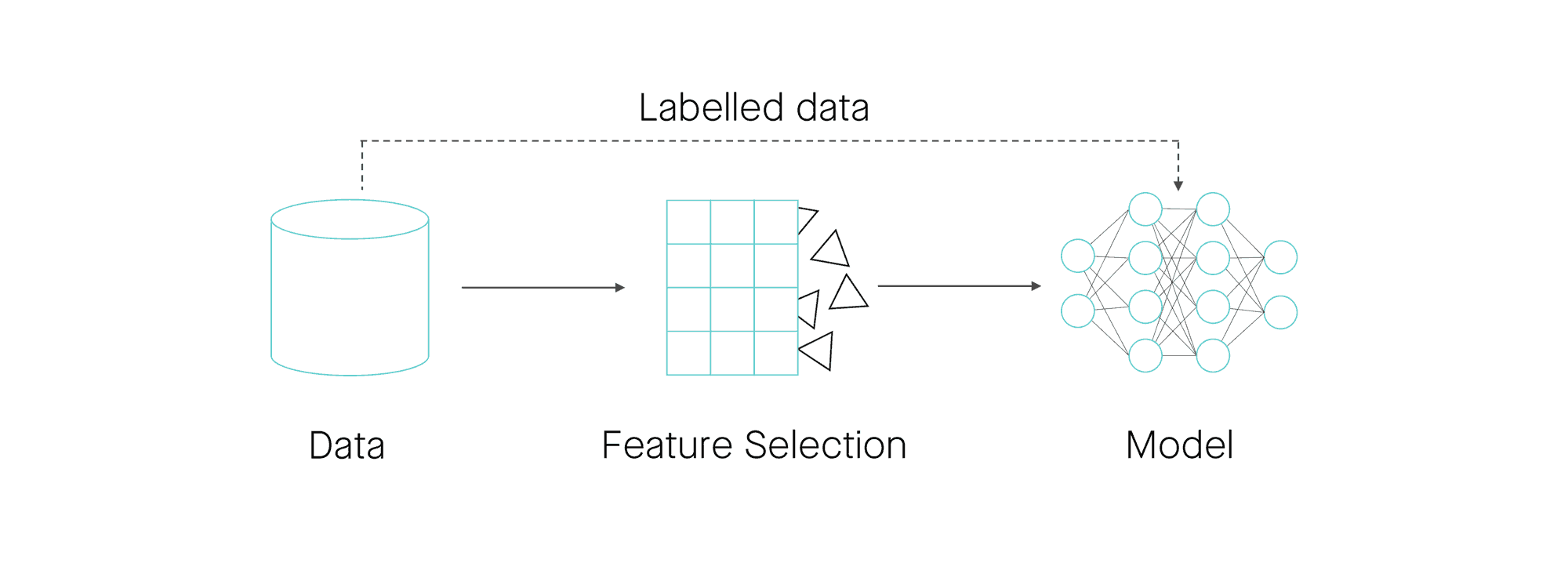 Figure 4: Making sense of data entails training ML models on certain features, but deciding which features are predictive requires sophisticated, modern techniques like BERT.
Figure 4: Making sense of data entails training ML models on certain features, but deciding which features are predictive requires sophisticated, modern techniques like BERT.
Beyond the feature selection challenge, perhaps the biggest barrier standing in the way of automated ticket triaging is the small data problem. Historically speaking, machine learning has relied on “big data”: datasets that are sizable enough to reveal patterns and generate insights. But the ticket history of a single organization is usually too small to power deep learning on its own; in fact, even large organizations with tens of thousands of IT tickets may not have enough data to get good results from deep learning, which in general requires a million-plus data points. And as we show in the illustration below, the actual number of tickets to learn from is far smaller than expected, since each round of filtering the tickets reduces the number exponentially.
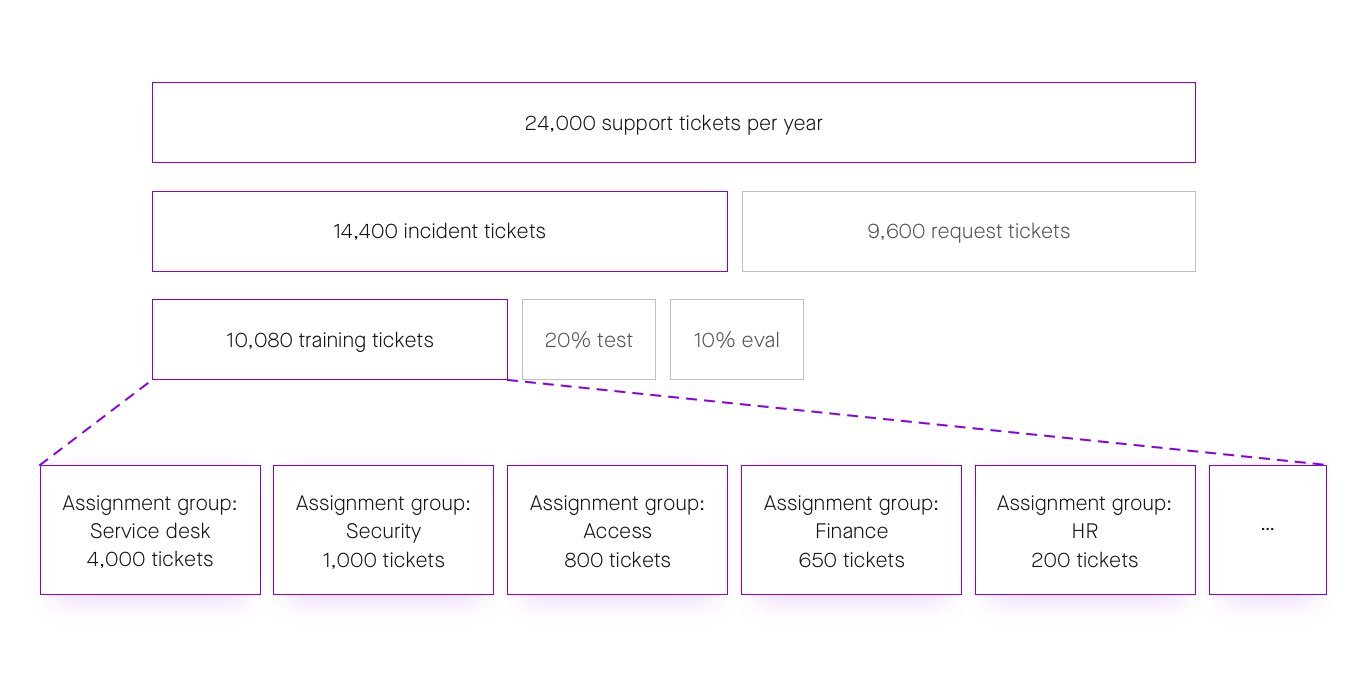 Figure 5: Even in a company with 2,000 employees like the one above, ticket triaging models must be able to cope with small amounts of data, since each assignment group only deals with a handful of tickets regarding a particular IT issue.
Figure 5: Even in a company with 2,000 employees like the one above, ticket triaging models must be able to cope with small amounts of data, since each assignment group only deals with a handful of tickets regarding a particular IT issue.
For ML models that learn from just one organization, the small data conundrum marks the end of the road, since each new ticket might be entirely unfamiliar to the model. It’s the equivalent of googling the word “platypus” and having the search results predicated on just your own previous search history about platypuses — which is likely nonexistent — as opposed to the billions upon billions of related searches that actually inform Google’s algorithms. Of course, as we learned, different organizations face different challenges in the IT domain, so generalizing between them isn’t easy. But insights about the similarity of words, as well as the role they play in determining a sentence’s overall meaning, are more universal. Again, that’s Part 2.
Achieving instant ticket triage with deep learning
The long delay that comes after submitting an IT ticket seems to be an unfortunate fact of life. Service desk agents are always busy, and as human beings, they’re inevitably susceptible to human error. Consistently assigning IT tickets to precisely the right resolver group, with all of the right information, in under a minute is simply not a realistic goal given the myriad assignment groups in most organizations. And while classical machine learning models attempt to address this problem by making automated routing decisions, they suffer from major shortcomings:
- Lack of context: Early ML models for automatic ticket triage tended to learn only from tickets’ short description and one or two other fields, ignoring a mountain of useful data.
- Reliance on guesswork: Absent the ability to analyze every field in a ticket, these early models forced the service desk team to guess ahead of time — and without sufficient knowledge — which fields would be the most predictive.
- Small data conundrum: By only ingesting tickets from a single IT service desk, these models failed to capture enough information to make effective routing decisions.
- Not grouping words by meaning: Without grouping each word by its broader category or attempting to understand its meaning in context, classical ML models couldn’t capitalize on the predictive power of employees’ descriptions.
But that, thankfully, is not the end of the story. A seemingly uncrackable code just a few years ago, the problem of automated ticket triage has today been overcome with deep learning and supporting techniques. To discover how, you’ll have to check out Part 2.
Contact Moveworks to learn more about how our deep learning automates ticket triage.


