
Table of contents
Over the last decade, we've seen an explosion of software tools designed to save us time. But while these tools should make life easier, learning to use so many applications — each with their own array of buttons, menus, and submenus — often has the opposite effect. The fundamental problem here is this language barrier between us and our technology: people communicate with conversation, not by clicking buttons and navigating through menus.
Last week, in Part 1, we analyzed attempts to overcome this language barrier with chatbots that engage users in scripted interactions. Across the board, these chatbots are unsuccessful because they don’t address the ambiguity and unpredictability of real-world conversations, which cannot be scripted out in advance. Ultimately, engaging users on their terms requires a new approach to both understanding natural language and managing conversation flow.
In this blog, we’ll explore how that new approach is streamlining human-computer interaction in two distinct ways:
- First, advances in natural language understanding (NLU) allow the latest chatbots to deeply grasp language by considering context
- Second, probabilistic conversational AI enables such chatbots to determine the ideal response on the fly, rather than sticking to a fixed script
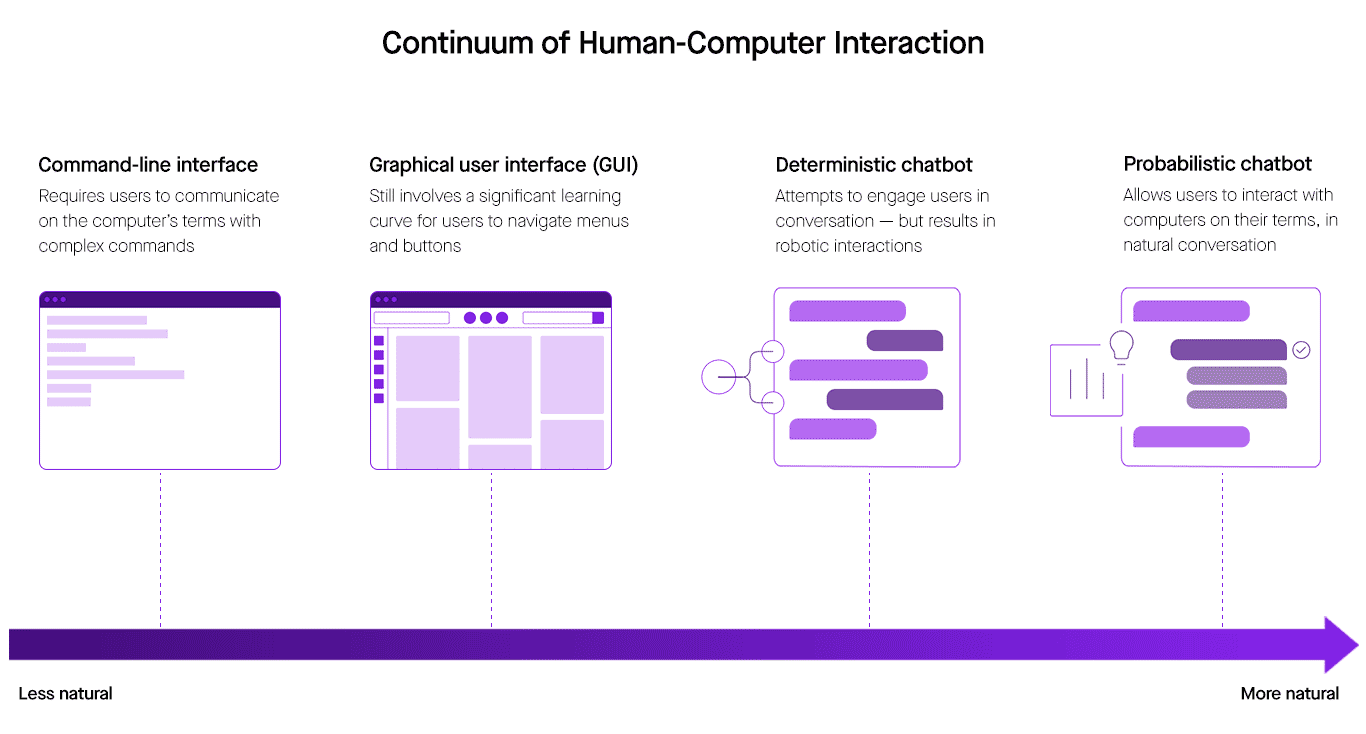 Figure 1: Overcoming the language barrier between humans and computers requires probabilistic chatbots, which engage users in natural conversation.
Figure 1: Overcoming the language barrier between humans and computers requires probabilistic chatbots, which engage users in natural conversation.
Conversation requires context
All of us have had bad experiences with chatbots. The question is, what does it take to build a good experience? Not surprisingly, if you want a chatbot that works, it needs a strong enough understanding of language to be conversational.
“Understand” is the key term here. Conventional chatbots rely on basic natural language processing (NLP), which entails analyzing the literal words in a given sentence. But simply processing words at a surface level is quite different from understanding the user’s intentions. That’s where NLU comes into play — not only parsing the words said, but also evaluating those words with the context that defines conversation.
So what is context? Context is shared, unspoken assumptions. It is all the external knowledge that people, unlike machines, naturally bring to conversation, and includes everything from current events to previous interactions to the location of the speaker. Simply put, conversation depends on context, and conventional chatbots fail precisely because they consider each sentence in a vacuum — as if it fell from the sky.
Of course, it’s still impossible to program a computer with the lifetime of context that each of us brings to our conversations. What we can do is approximate that intuition by using machine learning to decipher four types of context:
- Syntactic Context: By understanding the structure of a sentence, we can separate the signal of that sentence — its actionable information — from the noise.
- User Context: By considering key information about the user, such as their job title and their location, we can clarify requests that would otherwise be ambiguous.
- Domain Context: By taking into account terminology specific to the user’s organization and domain, we can surface information that is uniquely relevant to them.
- Historical Context: By acknowledging past conversations, we can accumulate knowledge throughout the bot exchange to understand the user’s underlying intent.
What’s clear from all of this is that a system capable of conversation must consider quite a lot of outside context: who is talking, how they phrase their requests, the circumstances of the conversation, and what they said a minute ago. After four years of working to solve this problem, we found that conversation without context is impossible.
The following four examples demonstrate how each kind of context plays a key role in conversation:
Syntactic Context
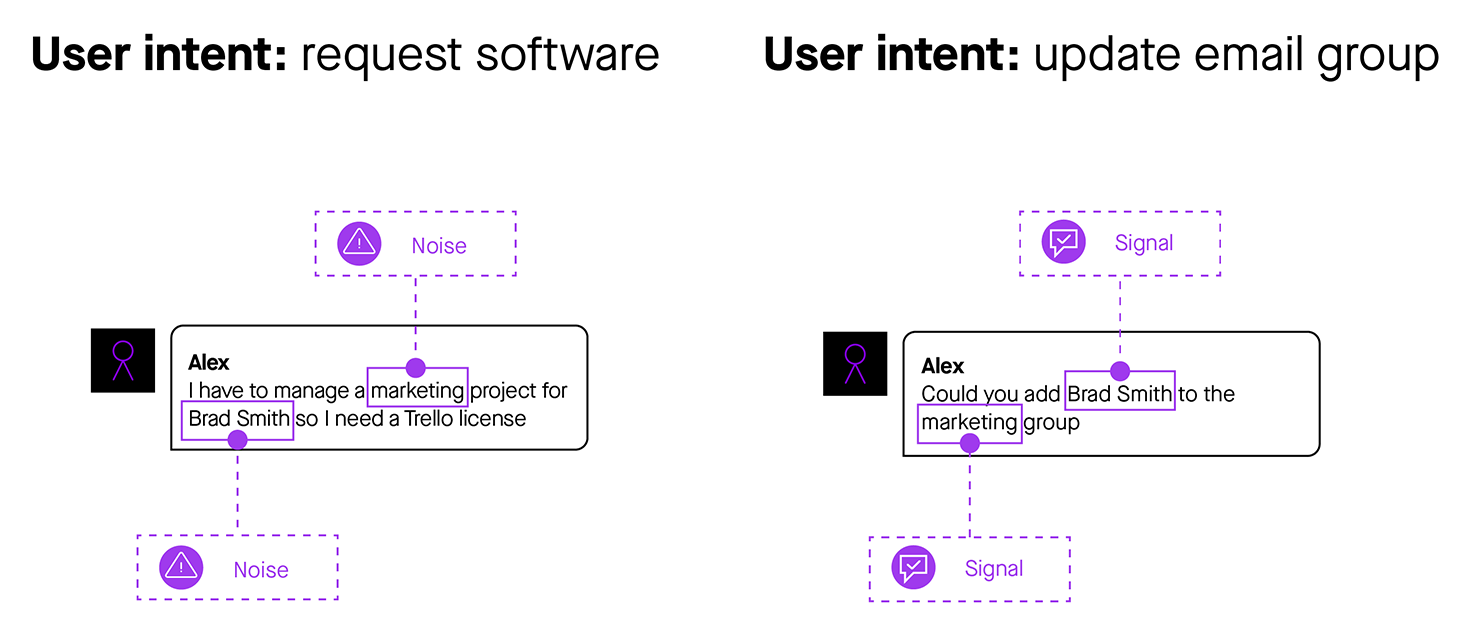 Figure 2: Understanding syntax allows chatbots to disambiguate similar user utterances, separating important signals from distracting noise.
Figure 2: Understanding syntax allows chatbots to disambiguate similar user utterances, separating important signals from distracting noise.
One of the fundamental challenges of understanding language is that the same words often have different meanings, depending on the syntax of the sentence. And determining the relevant meaning is the only way to decide which information in that sentence is actionable signal and which is irrelevant noise. This deep, syntactic knowledge takes a layer cake of machine learning techniques, from semantic frame parsing to entity inference to statistical grammar models.
In Figure 2, both requests for IT support use the words “marketing” and “Brad Smith.” But in the first case, these words are completely irrelevant to the task, while in the second case, all of those words convey the key message of the sentence. The ability to disambiguate different intentions from the same words is a major step toward natural conversation.
User Context
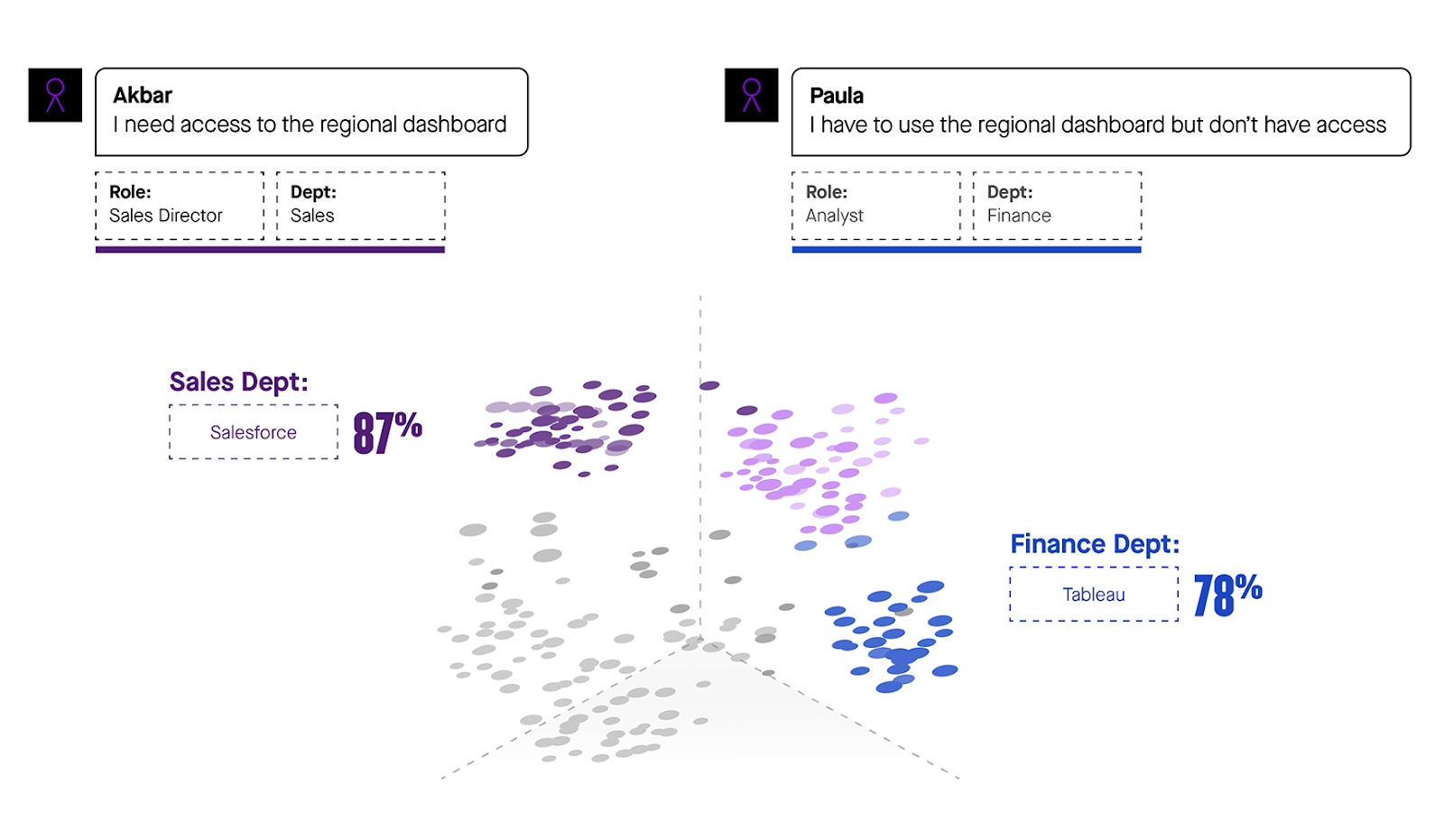 Figure 3: By taking into account the user, bots can deliver information specific to that individual user’s needs, based on their role, location, or department.
Figure 3: By taking into account the user, bots can deliver information specific to that individual user’s needs, based on their role, location, or department.
But understanding what a user wants takes more than just looking at syntax. Take a look at Figure 3. There are two very similar requests, both about accessing a regional dashboard. Before taking into account the users’ roles and departments, these requests appear identical. However, for Akbar, a sales director, our machine learning models tell us probabilistically that he needs access to Salesforce to view the relevant dashboard; whereas Paula, an analyst, needs access to Tableau, where her organization’s financial data lives.
The difference between Akbar and Paula is a perfect illustration of the difference between NLP and NLU. Rather than offering both employees the same response, an advanced NLU chatbot factors in their roles and departments to surface the right software. This knowledge of user context allows the bot to distinguish between many different dashboard options — with the same kind of intuition that a service desk agent would bring to the table.
Domain Context
 Figure 4: Domain context allows chatbots to deliver responses that are specific to a particular organization.
Figure 4: Domain context allows chatbots to deliver responses that are specific to a particular organization.
Already, by factoring in syntactic and user context, we’ve gone a long way toward demystifying the complexity of language, but there is another critical component of conversation left out of this picture.
Consider the question, “Where is John Lennon?” A search engine like Google answers this question with generic information about the Beatles’ lead singer. However, at Moveworks, we have customers who name their conference rooms after famous musicians, and other customers for whom John Lennon is an employee’s name.
To make conversational AI successful, we needed models built to understand that words take on different meanings in these different domains. Interpreting these ambiguities requires rich, contextual background for individual companies, enabling our bot to provide a conference room map in one case and employee contact information in the other.
Historical Context
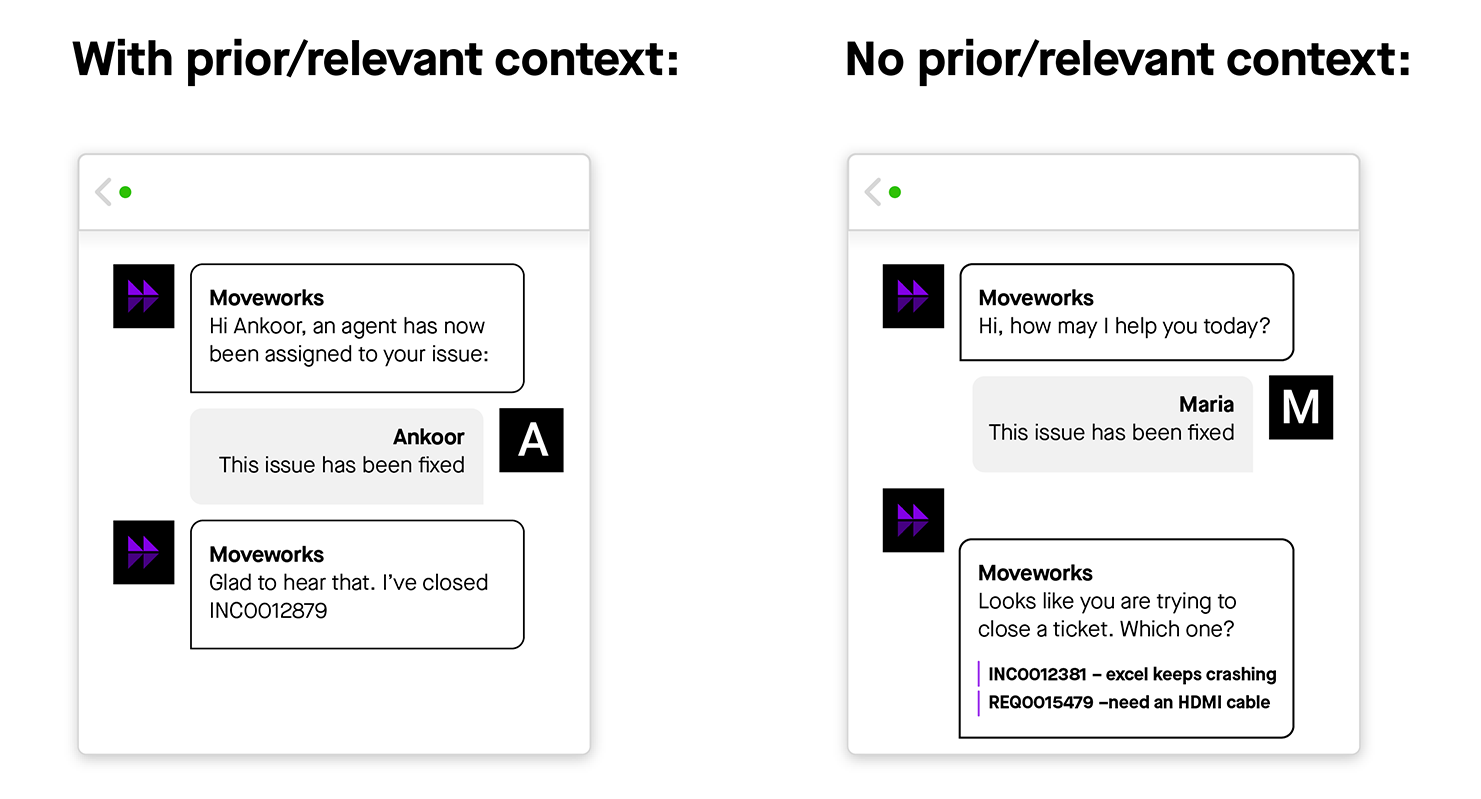 Figure 5: Awareness of past conversational back-and-forth helps chatbots disambiguate user requests and respond with relevant information.
Figure 5: Awareness of past conversational back-and-forth helps chatbots disambiguate user requests and respond with relevant information.
Historical context allows a bot to respond differently to the same utterance, depending on past conversations. While simple at first glance, “This issue has been fixed” can actually be quite a complex statement.
In Figure 5, both users said the same thing. In this first exchange, Ankoor has chatted previously with the bot. But in the second conversation, Maria’s statement comes out of nowhere. Since the bot doesn’t have enough context to answer Maria, it asks a follow up question to disambiguate.
When talking to our coworkers, we can immediately jump into complex conversations, because we have a shared past that informs the present narrative. Without even realizing it, we reference this entire history of interaction when responding to even simple requests.
As people, we are very good at consuming lots of context and allowing our experience and intuition to determine what is and isn’t important. For conventional chatbots, on the other hand, a lack of contextual knowledge makes it a challenge for them to follow real conversations. To build a chatbot that can keep up, you need to tackle NLU first by building models that understand context. Only then, can you work the second piece of the puzzle — delivering the right response.
Bidding for the right to respond
Every day, we benefit from probabilistic “bidding systems” without realizing it. For example, Google results vary depending on what is asked for. Sometimes, the search engine responds with a list of links, or a summary of a Wikipedia article, or a selection of videos, or a combination of all these results.
In a dynamic IT environment, providing relevant answers has an additional layer of complexity. Agents are always creating new knowledge base articles, adding new conference rooms, and deploying new tools to keep up with internal demands. Because there are so many changes and because these changes are so disparate, trying to hardwire the right answer into a chatbot creates brittle interactions that require constant maintenance to be of any help to employees. And that’s why a probabilistic approach that customizes answers to the user asking is so important. A bidding system based on machine learning models looks continuously at available actions and lets the models decide what is most relevant to the user.
An added challenge is that a conversation doesn’t look like a list of search results. A chatbot only gets one shot to provide a relevant and actionable answer; it can’t just throw 30 links on to the screen for a user to scroll through and hope one of them is relevant. A bidding system is able to deliver a single relevant answer. Sometimes the right response is to redirect the conversation to an IT agent; sometimes it means surfacing resources like a knowledge base article. Crafting a helpful response is not trivial and making the response easily understandable is an even greater challenge.
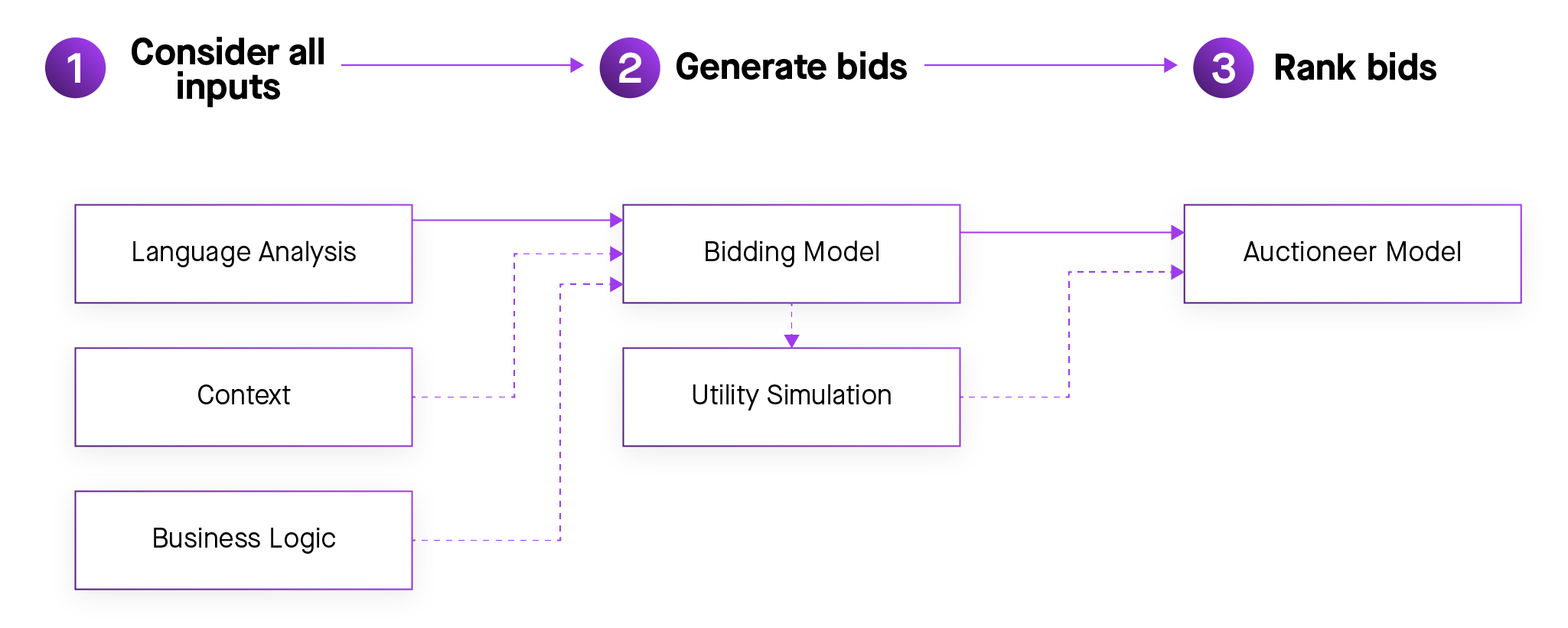 Figure 6: Making decisions based on models — not hardcoded rules — allows chatbots to adjust to changing context in real time.
Figure 6: Making decisions based on models — not hardcoded rules — allows chatbots to adjust to changing context in real time.
So let’s take a look at a common scenario for the Moveworks chatbot: a user asks for software access, in this case Adobe Acrobat Pro. The bot first evaluates critical context, such as the user’s job, department, and past support tickets. Then, it selects the best response by holding an auction where different possible resolution methods compete to demonstrate the highest value to the user.
There are many possible solutions to this question. The bot could surface a form, submit a new ticket, or provision software — just to name a few. Any of these actions would make sense, but the bot knows that instantly provisioning Adobe Acrobat Pro is the best response by understanding all the context of the original question. The user gets their software in seconds, and the bot stows away this information for future engagements with not only this user, but also with other users in this organization.
This leads us to another inherent benefit of machine learning — a chatbot learns from its past conversations. Recording employee feedback allows the bidding system to improve over time for the whole organization. Without a probabilistic system, a chatbot couldn’t learn from these real-life interactions and would continue to provide the same answer, right or wrong.
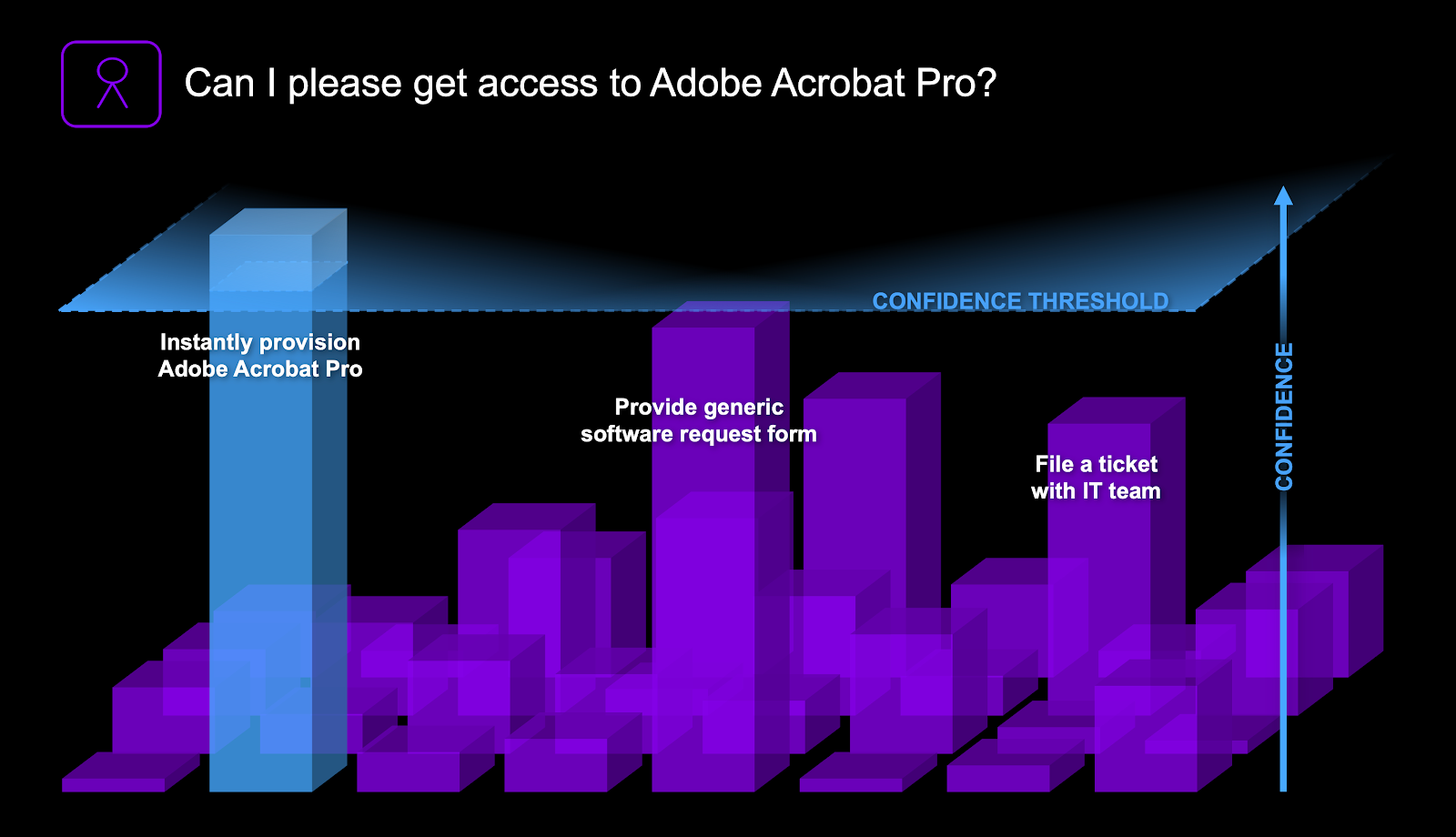 Figure 7: Different solutions bid for the opportunity to solve an IT issue. When one or multiple options reach the confidence threshold, a response is sent to the user in seconds.
Figure 7: Different solutions bid for the opportunity to solve an IT issue. When one or multiple options reach the confidence threshold, a response is sent to the user in seconds.
The conversational interface
Most user interfaces — from the graphical user interface (GUI) to conventional chatbots — share a flawed approach: trying to anticipate what users want. For GUIs, this approach takes the form of buttons and menus, while for conventional chatbots, it means scripting out fixed dialogs. Fundamentally, attempting to predict what a user needs is a dead end. People communicate with conversation, and conversation is unpredictable.
At Moveworks, we decided to go back to the drawing board. For one, we saw that addressing the contextual nature of communication requires more than simple natural language processing; it takes deep natural language understanding. And for another, we learned that seamless conversation depends on probability-based decisions, which determine the right response to a user’s request on the fly rather than in advance. This combination of advanced NLU and probabilistic machine learning makes the power of modern computing accessible to all people, regardless of their technical know-how.
Turns out, it’s simple to build a chatbot that’s complicated, but profoundly complicated to build one simple enough for everyone to use. That’s why Moveworks has spent the last four years creating and operationalizing hundreds of machine learning models — to completely eliminate the language barrier between us and our machines. Because beyond just our IT support chatbot, we’re building toward a future that’s truly conversational.
Contact Moveworks to learn how AI can supercharge your workforce productivity.


