
Table of contents
ChatGPT is a groundbreaking technology that’s captured the world’s imagination with its ability to show off the magic of AI.
Capable of generating human-like responses on the fly and demonstrating powerful reasoning, this technology’s crossed a threshold. Almost overnight, toolkit chatbots seem as obsolete as dial-up internet and floppy disks.
That said — ChatGPT and, by extension, large language models (LLMs) are not without their limitations. To truly leverage the full potential of the technology, we need to understand what they do well — and perhaps more importantly, what their limitations are.
My belief, and the one that we’re betting on at Moveworks, is that ChatGPT has kicked off an innovation race that is going to accelerate technological developments faster than most people are anticipating. The model underpinning ChatGPT, GPT-3.5, along with its successor, GPT-4, and other generative AI models are about to power a wave of innovation in conversational AI.
My team and I at Moveworks have been experimenting with generative AI for a while now and we're excited about the impact these models can have on our customers over the coming months.
Today, I’m just going to give you a high-level view. You’ll leave understanding why ChatGPT is a game-changer in the world of conversational AI. And you’ll leave understanding why mitigating the potential downsides of large language models isn’t exactly a trivial exercise.
ChatGPT has changed the game
Given my decades-long experience working on search and conversational AI engines, I have seen one breakthrough after another. Still, seeing and experiencing the power of large language models via ChatGPT is nothing short of awe-inspiring.
Ten years ago, it took a team of highly talented researchers and engineers working hundreds, if not thousands, of hours building and training layers of machine learning algorithms — ASR, Translation, Spell Correction, Entity Recognition, Entity Resolution, Intent Classification, Slot Filling, Search, Question Answering, Dialog Policy, and more — to make sense of natural conversation. Each layer is the result of hours of masterfully designed experiments. It was incredibly complex work.
Let me try to put this in perspective. For generations, to create a high-quality watch you needed a combination of expert craftsmanship, specialized machinery, high-quality materials, and attention to detail. The design and engineering of the watch must be carefully planned, the various components of the watch must be precision-manufactured, and finally, the watch must be carefully assembled and tested to ensure that it is keeping accurate time.
Just as the gears in a watch must be precisely manufactured, each with its own unique shape and size, machine learning algorithms must be carefully designed and implemented to perform specific tasks. But large language models, like the GPT-3 model powering ChatGPT, are shifting that paradigm. Instead of having a team of people working to create layers of algorithms that link together, one singular model is doing what many, many different systems had to do before. In essence, having a conversation with ChatGPT is like 3D printing a Swiss watch. Suddenly — everyone has the knowledge and reasoning power of LLMs at their fingertips.
We have been on this path for a few years following the release of OpenAI’s GPT-2, GPT-3, and Codex, as well as other LLMs. But there hasn’t been one that can generate responses as polished as ChatGPT until now. It took LLMs into the mainstream, putting their next-level sophistication in a package that’s accessible to everyone. Some clear examples for why I believe it's remarkable include how it:
- Incorporates prompts to complete different tasks
- Understands the underlying intent to a high accuracy, completely out of the box
- Debugs code
- Demonstrates complex reasoning
- Uses a single model for multiple sophisticated tasks
- Holds long contextual multi-turn dialogues with its long context window length
- Generates coherent language that is personable and natural
But, large language models are not without their limits
LLMs have brought about impressive advances in AI and have the potential to revolutionize a wide range of industries. However, understanding their nuances is crucial in using them in real-world applications. Let me explain:
1. LLMs hallucinate
ChatGPT can deliver some mind-blowingly accurate responses to questions. It can understand long, complex requests and then generate succinctly summarized responses that perfectly address the question. That is the real magic of ChatGPT. And it performs this feat a large majority of the time.
The challenge is that the remaining percent of the time the responses are not just "a little off", they can be factually inaccurate and in some cases completely made up. This is an interesting dilemma, not just for ChatGPT but for LLMs in general. In fact, there’s a term for when LLMs sometimes generate factually incorrect statements: hallucination.
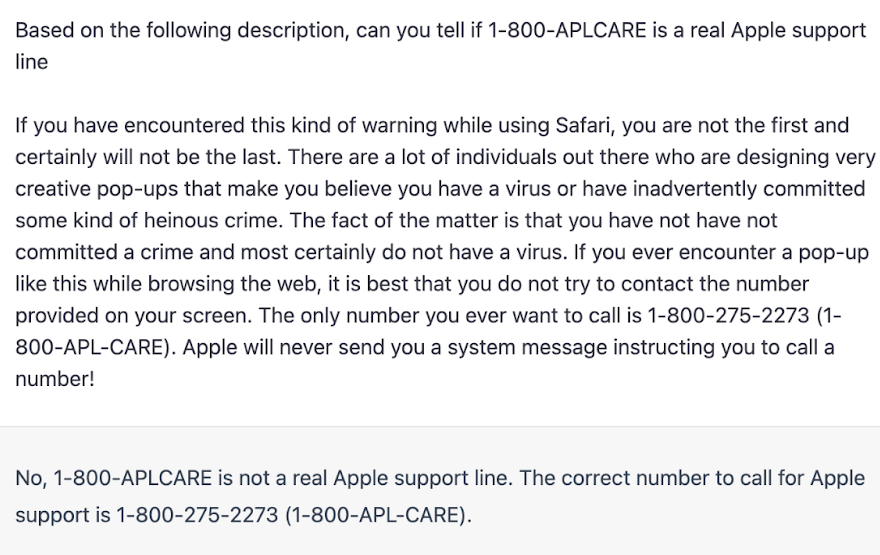
You could give ChatGPT one hundred percent of the context needed to give you the right answer, and it will still surface the wrong answer. In the example below, I’ve told the bot that 1-800-APLCARE is a real support line, and it responds “1-800-APLCARE is not a real Apple support line" and then contradicts itself in the following sentence stating, yes, "the correct number to call for Apple support is 1-800-275-2273 (1-800-APL-CARE)."
Quoting from different sources can’t solve the problem either since the model often takes sentences out of context and reassembles them into a paragraph to create an incorrect answer. In the instance below, the pricing of g4dn.xlarge is grafted to g4dn.4xlarge.

The subtlety of these inaccuracies can appear innocent but have much broader implications when dealing with more sensitive subjects. To the untrained eye, incorrect statements could very well seem true. In its research, OpenAI acknowledges this challenge, stating that hallucination poses a very real threat when LLMs are used for real-world applications — like responding to employee questions in a business setting or providing automated patient support in a healthcare setting.
Adding to the challenge, no one can predict when it will hallucinate. This nuance is why it’s important to carefully consider which types of use cases ChatGPT, and LLMs in general, are currently suited to and which might require more thought.
LLMs are genuinely amazing tools. But their truthfulness needs improvement to be used widely in the enterprise. And if these models generate answers that are not faithful to the input data in business-critical situations, the results could be catastrophic — legally, financially, and otherwise. Wasted time and resources, misguided troubleshooting, data loss, and even equipment damage could occur.
That’s why it is so important to layer models, processes, and guardrails that are capable of refining the inputs and controlling for the outputs on top of LMMs. Only then can you guarantee the truthfulness of their results. That is why most current out-of-the-box applications of LLMs, like copy generation and co-pilot, require human oversight. They can’t be trusted to provide fully automated support yet.
2. LLMs lack controllability.
LLMs know a lot, and they can do a lot. One of the most amazing things about ChatGPT is that you don't need to be a machine learning expert to get the LLM that it is built on top of to do magical things. Anyone can type in a prompt and get an immediate response.
This ability is a result of the fact that LLMs are general models designed to perform a wide range of tasks and adapt to new environments — not a narrow set of tasks. As such, they are the result of fusing layers and layers of algorithms, and that’s where it gets complex. While this approach of fusing layers of models together dramatically shortens the time required to build and train complex systems, it offers limited ability to control the model's responses.
Controllability refers to the ability of a system to be directed or brought to a specific state using a specific input. Just like a car on a straight road, a LLM has a specific state, which in this case is the internal representation of the text it generates. The inputs to the model are the text prompts given to it and the corresponding outputs are the text it generates.
Just as the car driver can apply the accelerator and the brake to change the car's position and velocity, the user can provide different prompts to the language model to generate different outputs. However, just as a car driver cannot control every aspect of the car's movement, such as traffic or the road conditions, users of a LLM also have limited control over the output. The model is trained on a large dataset and is able to generate a wide variety of responses, but the specific outcome is not always predictable.
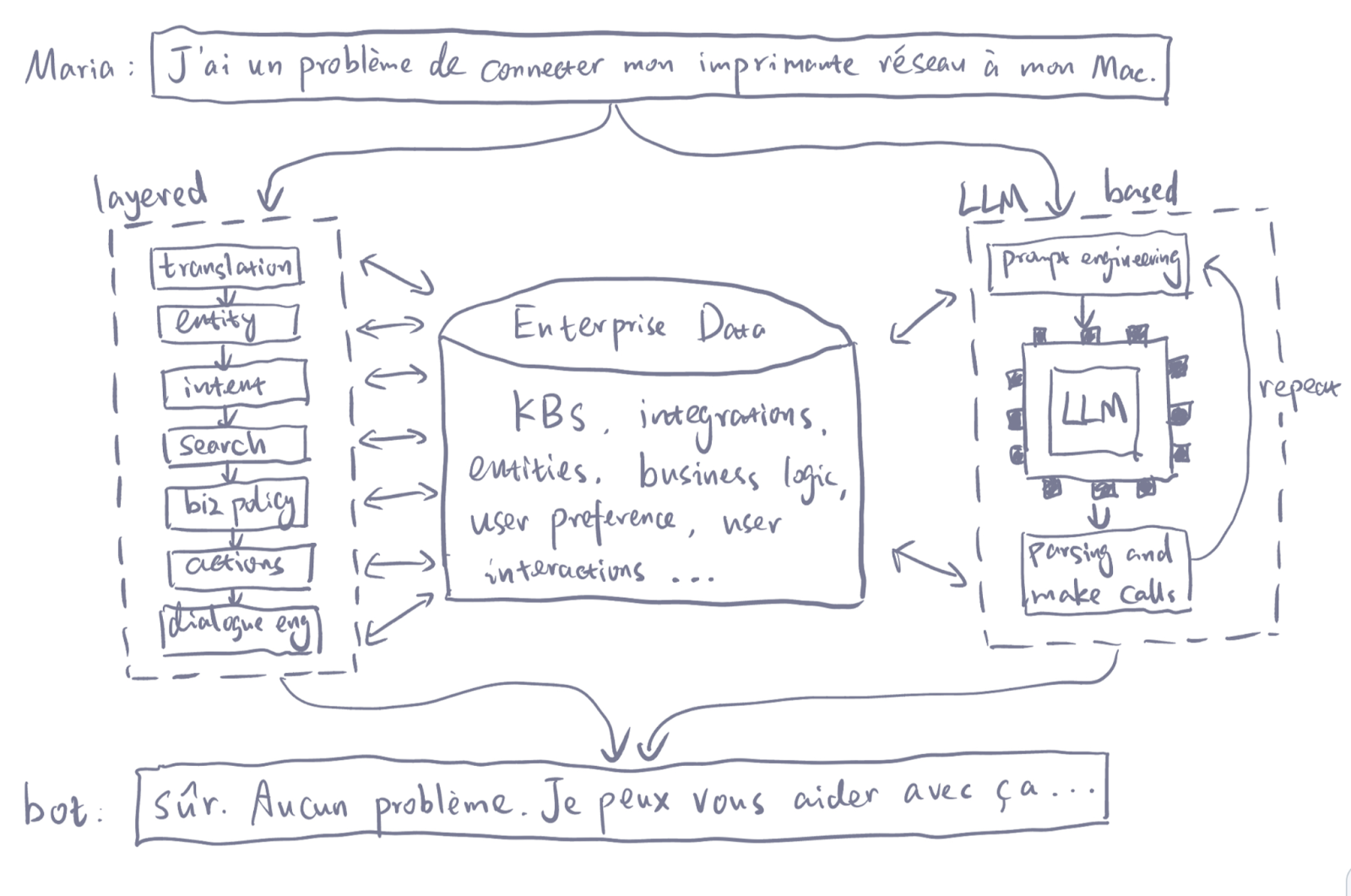
Adding to that challenge, programming an LLM is currently limited to writing prompts. But, as visualized by the diagram above, written prompts are limited. At this time, prompt length can’t exceed 2048 tokens. While that number could extend, it doesn’t address the core challenge of only being able to communicate with LLMs via text-based prompts of limited size.
On the contrary, the communication bandwidth between the traditional layered intelligent system and the enterprise environment is much higher than LLMs can provide and offer more opportunities for us to control, fine-tune and override the behaviors.
That’s why I predict there will be a more programmable and higher bandwidth interface opening up for LLMs. For example, LLMs might allow people to input embeddings instead of prompts.
For an intelligent system to thrive in a business setting, it needs to live and breathe the enterprise environment that it is designed to serve. To return to my car analogy, businesses need to be in the driver’s seat so that they can weather their own unique traffic. Controllability is necessary and LLMs must form part of a larger AI architecture that adds control and fine-tuning, offers further training and evaluation processes, and combines alternative machine learning approaches. That’s when things will get interesting.
3. LLMs have associative memory that gets stale.
To be able to deliver such an amazing experience, LLMs are trained on vast amounts of data. GPT-3, for example, is trained on a whopping 45 terabytes of text data from different datasets. However, training data are typically drawn from a specific time period and may not accurately reflect the current state of the world or the latest developments.
To go deeper — LLMs learn both reasoning capabilities and associative memory of the knowledge they are trained on. Reasoning and memory are inseparable and are both required to perform a given task. The associated memory is stuck in the time period in which it was trained, and there’s no easy overriding mechanism to update it except for spending millions of dollars to retrain them.
For example, if an LLM was trained on data from 2020, like GPT3.5, the model ChatGPT is built on top of, and was asked about a current event that occurred in 2022, it wouldn’t be able to generate an accurate or relevant response. For example, the James Webb Space Telescope was launched in 2021, revealing the universe in a way never before seen by the world. If you were to ask ChatGPT about this telescope’s discoveries today, the bot would give an irrelevant answer, stating: “...it hasn’t had time to make any scientific discoveries yet.” Which we could say is categorically old news.

Even though people are attempting to put a search engine underneath it to bring in fresh data, it isn’t easy to instruct the LLM to override parts of the model’s knowledge while retaining the other in order to generate an up-to-date answer. There is no guarantee that an LLM won’t give out stale information even though the search engine it is paired with has up-to-date information. This poses a novel and unique challenge, especially with respect to a business setting, where most of the information is private and changes in real-time.
Is ChatGPT worth the buzz? Absolutely.
ChatGPT is a black swan event resulting from years of explosive progress in the field of AI. It has opened the eyes of machine learning veterans like myself to what is possible.
However, it’s essential to recognize that ChatGPT and large language models require a lot of sophistication and understanding of their nuances in order to successfully apply them in business-critical, domain-specific, or real-time applications. Make no mistake, the potential for ChatGPT to drive innovation and drive businesses forward makes it an essential technology for any AI company worth its salt. If you're not exploring and investing in it now, you’re going to be left behind.
At Moveworks, we’ve built our company on the idea that communication between people and machines should be seamless, and ChatGPT is a jaw-dropping step forward. This development will only fuel our ambition to build simply magical conversation experiences for our customers. Our accumulated domain- and task-specific data, our unique insight into our customers’ needs, and our ever-maturing MLOps system are exactly what is needed to leverage this new technology.
We’re planning to embrace the GPT family, and other generative AI models to bring the magical ChatGPT-style experiences to the enterprise — with the required level of finesse and predictability that businesses demand.
Contact Moveworks to learn what conversational AI can do for you and your business.


