
Table of contents
The rise of large language models has ushered in a new era of conversational AI. Yet, when deployed in complex enterprise settings, even the most capable models can stumble. These models struggle with specialized terminology, procedural nuances, and industry-specific data.
To excel in the workplace, an AI needs more than raw technical prowess — it requires extensive training on comprehensive, domain-specific data.
Today, we’ll dive into MoveLM™, a large language model customized for the workplace. MoveLM marks a major milestone in our mission to develop large language models with enterprise expertise. Through meticulous data annotation, state-of-the-art data generation, specialized training, and rigorous benchmarking, we have created an LLM designed explicitly to tackle the enterprise tasks that hold your people back.
While LLMs such as OpenAI’s GPT-4 boast impressive technical benchmarks, MoveLM outpaces them on tasks that matter most to your business — understanding custom workflows, interpreting industry data, and even adapting its communication style. It also provides blazingly fast response times through advanced inference optimization, all without using customer data for model training.
Today, we’ll provide an inside look at the methodologies that enabled MoveLM's unprecedented effectiveness, discussing:
- The specialized enterprise data curated to train MoveLM's understanding of the workplace
- The rigorous training process that shapes MoveLM's conversational abilities
- The enterprise-focused testing to evaluate MoveLM's performance
- The proactive risk management strategies integrated throughout MoveLM's development
MoveLM's enterprise training data advantage
Moveworks' machine learning thrives on our dedication to curating specialized enterprise data. This high-quality training data enables MoveLM to achieve a nuanced understanding of how employees ask for help at work.
Over six years, Moveworks has aggregated over 500 million support tickets, facilitated approximately 14 million bot conversations, ingested over 400,000 knowledge base articles, and collected over 35,000 forms. This comprehensive enterprise dataset powers MoveLM's abilities to handle real-world business scenarios.
With Moveworks' proprietary training data at its core, MoveLM sets itself apart in its ability to deliver intelligent, conversational AI tailored for the modern workplace. But this is just the high-level view. Let’s go deeper.
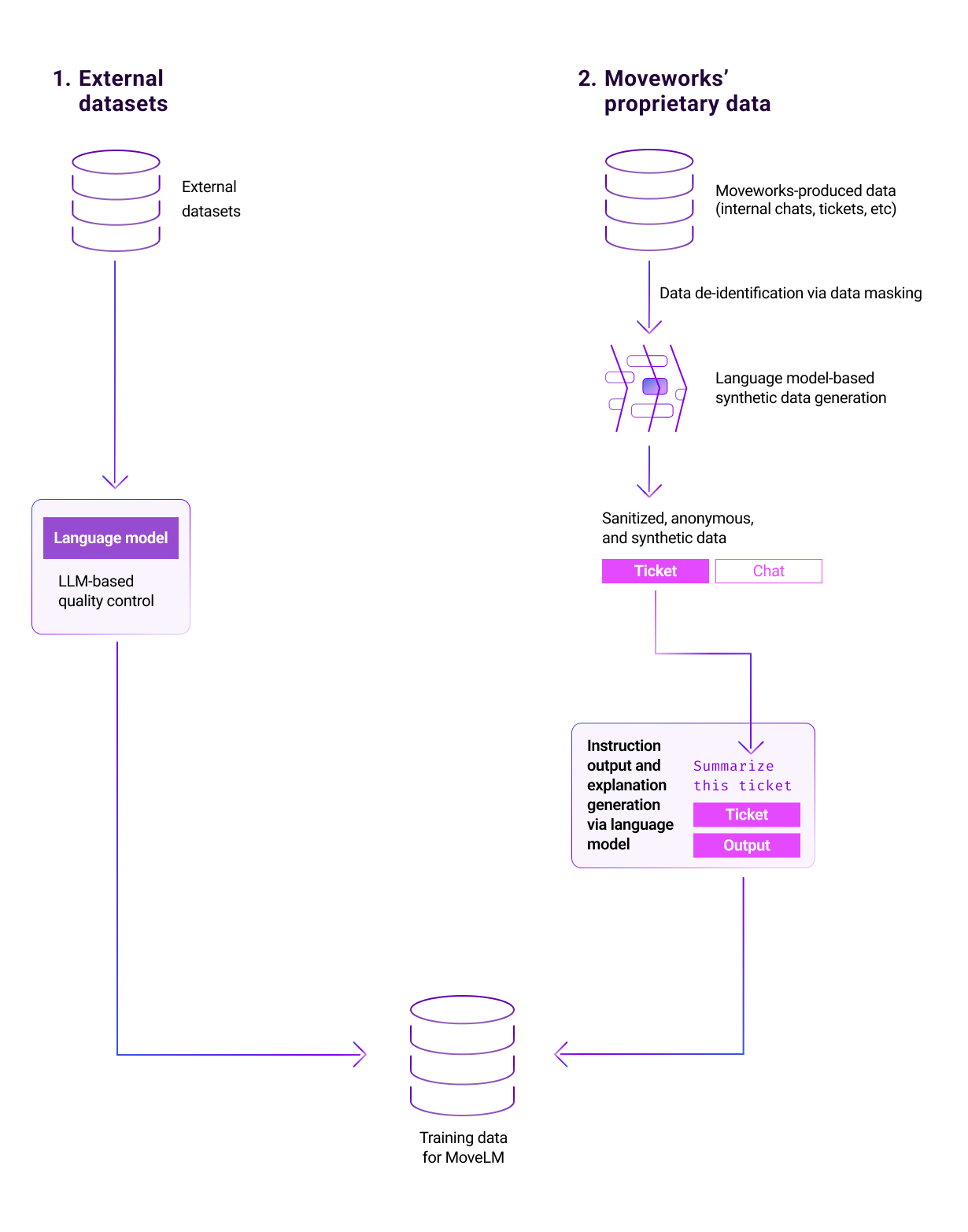 Figure 1: Moveworks' six years of specializing in enterprise use cases gives MoveLM the ability to understand and resolve employee support requests in business settings.
Figure 1: Moveworks' six years of specializing in enterprise use cases gives MoveLM the ability to understand and resolve employee support requests in business settings.
Leveraging years of proprietary enterprise data
Our first critical advantage is our ability to tap into an extensive repository of proprietary enterprise data that has been fully anonymized prior to model training. This repository provides a robust foundation for our model. However, it required extensive data masking, privacy engineering, and careful adaptation into instructional input/output formats tailored for MoveLM's training.
Through an expert annotation team, we extracted high-quality annotated datasets for tasks most commonly used to understand user queries in enterprise settings. These included traditional tasks like entity typing, intent classification, question answering, and slot filling. And, it also included new tasks that became a possibility due to the incredible reasoning capabilities of LLMs, such as function calling. Converting these datasets created over 60,000 real-world examples to teach nuanced business concepts.
By converting these diverse datasets into a consistent format showing instructions and corresponding actions, we created hundreds of thousands of real-world examples to teach MoveLM nuanced enterprise concepts that generic models struggle with.
This conversion process helped to tap into our vast amount of data and mold it into a usable form for MoveLM. This was a critical step towards creating a model that understands complex instructions and, crucially, how to execute them.
Expanding training data through state-of-the-art data generation
Seeking to expand our dataset, we leveraged MoveLM itself through responsible self-instruction techniques. By exposing MoveLM only to anonymized excerpts from tens of millions of employee service, HR, IT, and customer chat logs within Moveworks' secure environment, we could generate new and diverse training examples.
By seeding MoveLM with anonymous excerpts, we have produced over 500,000 new demonstrations for interpreting instructions and responding properly in business contexts. These demonstrations included diverse multi-turn dialogs between users and the LLM copilot, where the copilot provides helpful responses to users for any queries related to solving IT and HR issues, and examples where the copilot leverages custom user-provided “plugins” to solve enterprise issues.
This augmented, model-generated data significantly increased the volume and diversity of instructional data for fine-tuning MoveLM. The new scenarios also expanded the variety of situations MoveLM could learn from, enhancing the robustness it needs for the modern enterprise. Through privacy-focused self-instruction, we could grow MoveLM's skills for assisting employees while upholding our commitment to customers' data security.
Incorporating diverse open-source data
While our proprietary datasets are invaluable, it's also crucial to incorporate external perspectives to ensure our model can generalize beyond enterprise-specific tasks. To complement our sources, we integrated over 500,000 instruction examples from publicly available datasets such as Dolly, Natural Instructions, and OpenAssistant.
This supplemental data increased exposure to task formats and terminology that may be outside the scope of our internal data. The diversity of language and phrasing prepared MoveLM for generalizable reasoning beyond our use cases.
The cumulative result of leveraging years of anonymized data, generating supplemental synthetic data, and incorporating external datasets was over 1.2 million high-quality, specialized training examples. This focus on depth over breadth shaped an enterprise-fluent model.
How we trained MoveLM to thrive in a workplace environment
Of course, high-quality training data is just the first step. Equally important is the rigorous training process that transforms the raw data into meaningful skills. Here, we detail the techniques we developed to impart MoveLM with business acumen and equip it for intelligent assistance across the enterprise.
Refinement via iterative and phased fine-tuning
The foundation of MoveLM's training is supervised fine-tuning using causal language modeling (CLM). This approach enabled the model to make probabilistic predictions on the copilot’s output based on instructional prompts.
Our methodology involved the comprehensive exploration of state-of-the-art models like Meta’s Llama 2 and CodeLlama (7B/13B parameters) and established 6B/7B parameter models like MosaicML's MPT, Stability AI's StableLM, and GPT-J models.
We conducted multiple training phases, each introducing distinct datasets from our proprietary, augmented, and external sources. This iterative approach enabled us to incrementally adapt MoveLM and precisely assess each dataset's impact on improving enterprise fluency.
The first phase included fine-tuning on aggregated external datasets. During this phase, we steered the model to learn core reasoning and instruction-following capabilities.
Afterward, MoveLM was fine-tuned on a high-quality, diverse synthetic dataset. This second phase allowed MoveLM to learn multiple core tasks used in Moveworks’ production copilot to solve various enterprise issues.
Lastly, the model was fine-tuned via the state-of-the-art explanation tuning algorithm using our most complex and challenging use cases. At this phase, the model was trained to produce optimal copilot output as well as a step-by-step chain of thought reasoning.
The result was versatile 1B, 3B, 7B, and 13B parameter LLMs trained via state-of-the-art training and data generation algorithms and rigorously evaluated across multiple datasets. At Moveworks these models are dynamically chosen depending on the difficulty of the tasks we are solving. To sum up, exploring multiple models with distinct datasets allowed precise fine-tuning tailored to enterprise needs.
Optimizing for data quality and optimal training hyperparameters
While the model type and training algorithms are critical factors impacting the performance of LLM, data quality and training hyperparameters also significantly affect overall model quality. To ensure the model is trained with high-quality training data, the MoveLM team implemented a data preprocessing pipeline that includes logic to:
- Semantically de-duplicate data in the training dataset
- Filter training data using a language model based on self-reflection
Semantic deduplication removes a subset of examples from the training data corpus if sufficiently large semantically similar examples have previously been found in training data. This approach ensures that the model is trained on a diverse set of language patterns and steers the model not to overfit a particular behavior.
Self-instruct is an algorithm where a language model is asked to identify high-quality and low-quality training examples via prompting. Using this approach, the MoveLM team filtered out training examples where the copilot’s output was not helpful, contained hallucination, or generated toxic language.
Furthermore, we extensively tuned key hyperparameters to maximize training efficiency, including model type, number of parameters, batch size, learning rate, warmup ratio, weight decay, optimizer choice, and scheduler. Hyperparameter optimization was crucial because settings like batch size and learning rate significantly impact model convergence and stability.
Leveraging Moveworks’ internal training infrastructure that allows us to train LLM in a config-driven fashion, we could train LLM using a diverse set of configurations. These optimized hyperparameters enabled us to maximize training efficiency and quickly fine-tune MoveLM to excel on various enterprise tasks and datasets. Careful hyperparameter tuning was essential to develop an enterprise-ready LLM with rapid and stable training.
Efficient memory management with DeepSpeed
To overcome the substantial computational demands of large model training, we integrated DeepSpeed and its advanced optimizations, such as ZeRO stage 3 and ZeRO-Offload.
Techniques like partitioned optimizer states, gradients, and parameters across 8 GPUs delivered significant memory savings so we could train MoveLM efficiently at scale. In this case, DeepSpeed enabled training the 7B parameter MoveLM with 3000 token length on A100 40GB GPUs in only around three days per model.
Evaluating MoveLM's performance in an enterprise environment
To accurately benchmark MoveLM's capabilities, we developed a robust evaluation framework adhering to key principles:
- Reproducibility: Our config-driven approach enables replicable experiments by preserving settings like datasets, metrics, and text generation parameters. This maintains integrity and allows verifying external model changes.
- Flexibility: With customizable transformations, our framework adapts to diverse models and datasets. It effortlessly ingests and outputs varied formats for analysis.
- Comparability: The ability to compare model outputs side-by-side given the same inputs provides actionable insights into why one model outperforms another.
This Moveworks Enterprise LLM Benchmark was crucial for thoroughly assessing MoveLM before deployment. It enabled evaluation using real-world enterprise data, flexible comparative analysis between models, and qualitative insights beyond metrics alone.
Specifically, our benchmark used proprietary test sets curated from diverse enterprise tasks we encounter daily, such as intent classification, document relevance ranking, slot filling, and more. By leveraging real examples of complex support tickets, customer conversations, HR documentation, and other in-house data sources, we could evaluate how MoveLM would perform the nuanced tasks required in an enterprise setting. Public benchmarks often lack the diversity and depth of business-domain examples we require.
Our framework also allowed flexible comparison of MoveLM against competitive models like GPT-3.5 Turbo by tailoring specific evaluation scenarios and test sets optimized for enterprise domains. We could go beyond standardized academic benchmarks and craft targeted experiments to analyze critical differences in business performance.
Finally, qualitative analysis of side-by-side model outputs enabled us to identify strengths and weaknesses beyond top-level metrics alone. Afterward, common failure patterns and weaknesses of the MoveLM model were incorporated into our data generation pipeline. By comparing generated texts given identical inputs, we gained more nuanced insights into the behavior of the MoveLM model.
Results of the Moveworks Enterprise LLM Benchmark
The rigorous Moveworks Enterprise LLM Benchmark validated that our specialized training methodology enabled MoveLM to achieve outstanding performance on critical enterprise tasks.
Issues that arise in enterprise settings can be extremely complex. For example, users and enterprise copilots may interact in multi-turn dialog in which users may reference issues or IT tickets mentioned previously, and resolving enterprise issues may require calling organization-specific APIs — such as creating IT tickets, requesting PTO, or searching for articles.
Therefore, a truly intelligent enterprise copilot must be able to correctly understand user issues in multi-turn dialog, correctly identify situation-specific, organization-specific APIs to call, and be able to summarize the output faithfully to the user.
For the Moveworks Enterprise LLM Benchmark, we evaluate MoveLM with 7 billion parameters on function call and core reasoning tasks. Here, the model is provided with a list of organization-specific enterprise APIs as well as dialog between the user and enterprise copilot. The provided enterprise APIs are organization-specific.
 Figure 2: Example APIs provided to the enterprise copilot for selection. These APIs include a diverse set of organization-specific APIs that can be used to resolve IT/HR issues.
Figure 2: Example APIs provided to the enterprise copilot for selection. These APIs include a diverse set of organization-specific APIs that can be used to resolve IT/HR issues.
The model was then evaluated on:
- Function calls: The model's ability to understand natural language inputs in context, including multi-turn dialogues and available enterprise-specific APIs that may help resolve a user's issues. The model is evaluated on its ability to correctly choose the right enterprise API to use to resolve IT or HR issues, as well as its ability to intelligently parse and extract correct arguments for the enterprise API given the dialog with the user.
- Helpful assistant replies: The model’s ability to provide helpful responses to users on creative tasks such as email generation. This test evaluated the model's ability to summarize complex API outputs in a way that is clear and useful to the user.
- Generalizable intelligence: Beyond specialized enterprise tasks, we tested the models on the StrategyQA dataset. This dataset evaluates a model's ability to reason, answer questions, and summarize information.
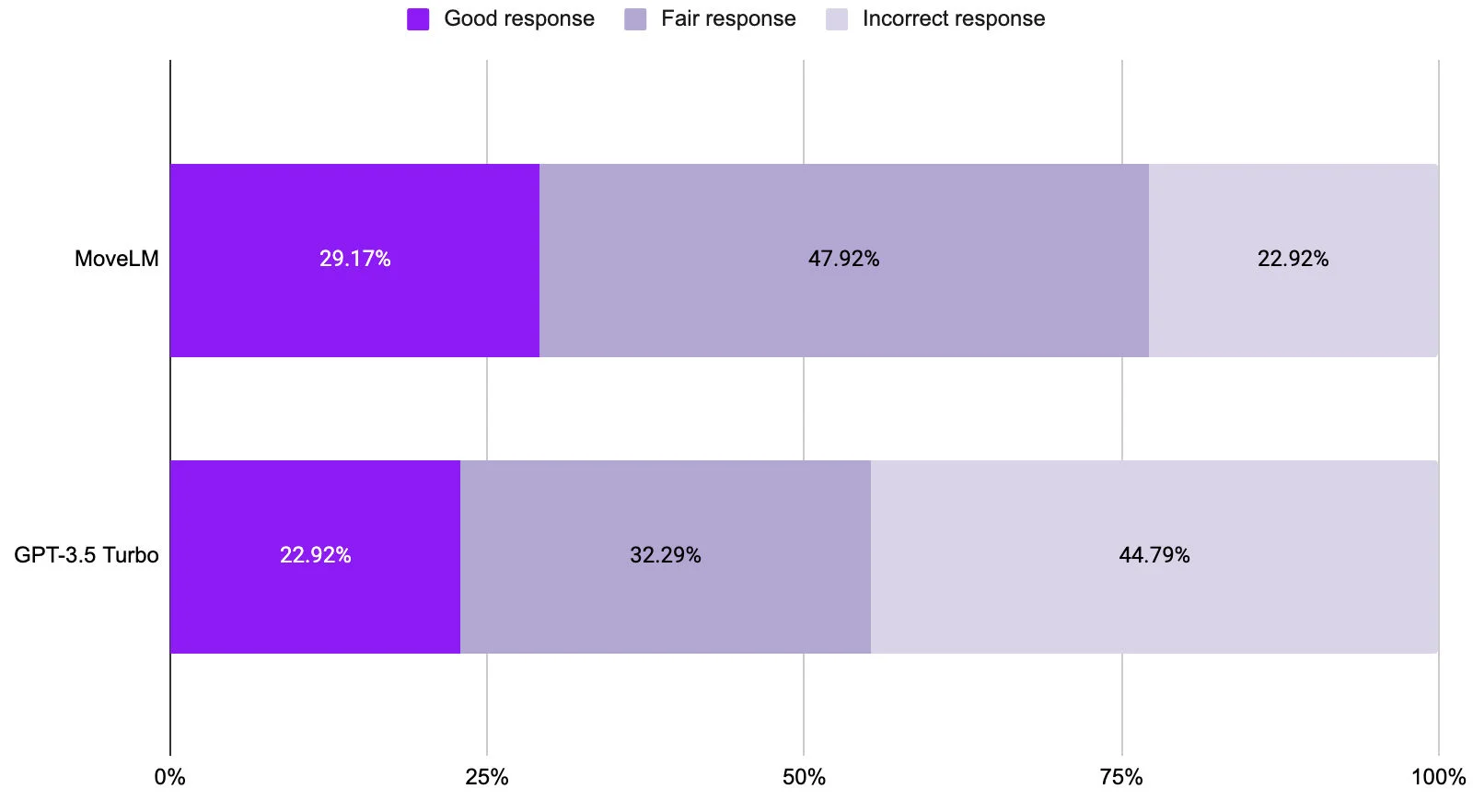 Figure 3: Evaluation results comparing MoveLM and GPT-3.5 Turbo on the enterprise function call tasks. MoveLM consistently selected more appropriate APIs than GPT-3.5 Turbo.
Figure 3: Evaluation results comparing MoveLM and GPT-3.5 Turbo on the enterprise function call tasks. MoveLM consistently selected more appropriate APIs than GPT-3.5 Turbo.
On the function call evaluation, the 7 billion parameter MoveLM significantly outperformed GPT-3.5 Turbo. Based on side-by-side comparisons by Moveworks' annotation team, MoveLM significantly outperformed GPT-3.5 turbo model on function call tasks. MoveLM was able to understand multi-turn dialog with the end user and propose correct enterprise functions to call 77% percent of the cases, while GPT-3.5 Turbo model output was correct only 55%.
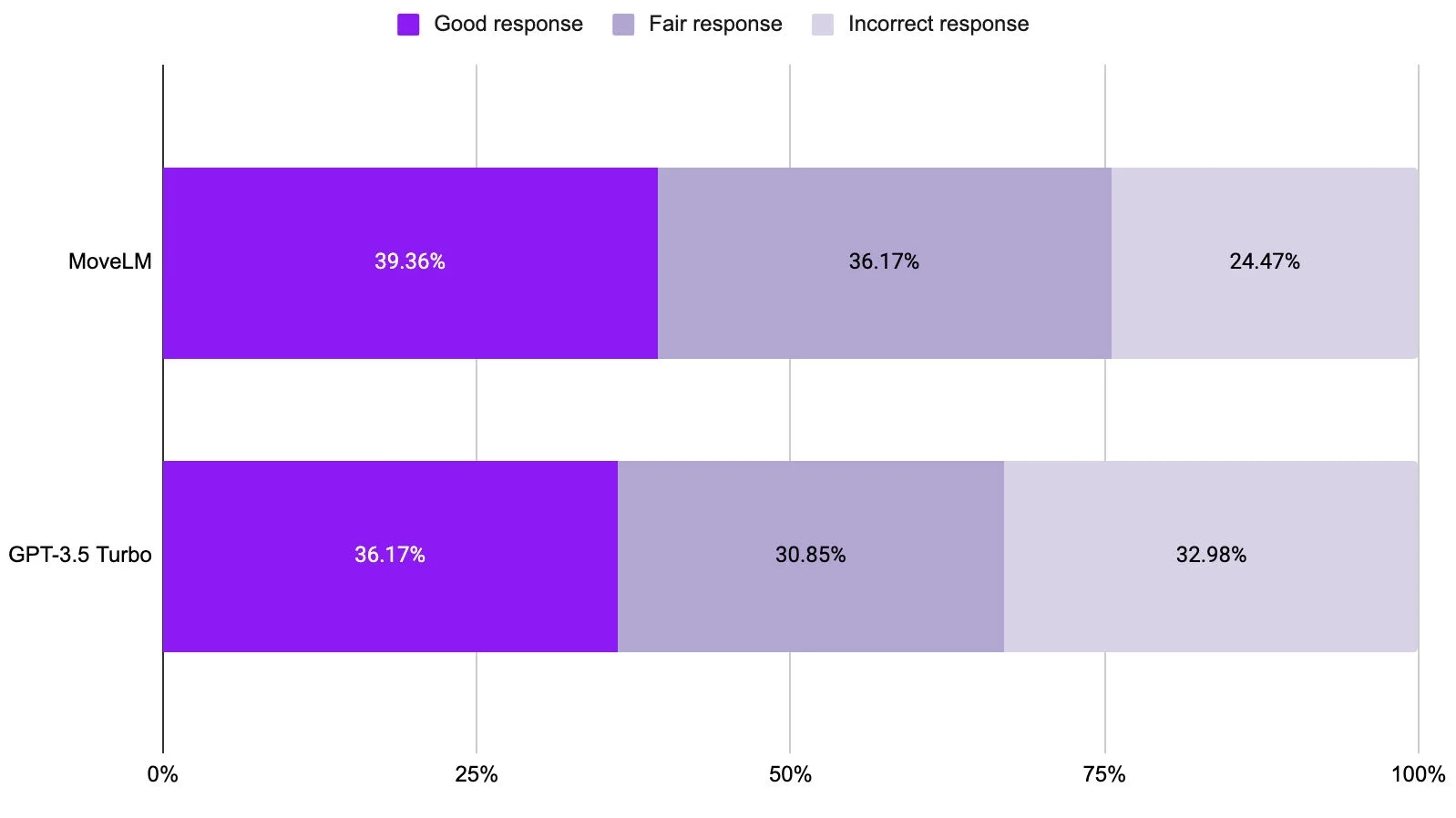 Figure 4: Evaluation results comparing MoveLM and GPT-3.5 Turbo on providing helpful user replies. MoveLM consistently provided more helpful responses than GPT-3.5 Turbo.
Figure 4: Evaluation results comparing MoveLM and GPT-3.5 Turbo on providing helpful user replies. MoveLM consistently provided more helpful responses than GPT-3.5 Turbo.
On the helpful user reply evaluation, we accessed the model's ability to return helpful responses to users and also follow complex guidelines such as adding citations and following strict style guidelines. MoveLM had good or fair output 75% of the time, while GPT-3.5 Turbo output was good/fair 66% of the time.
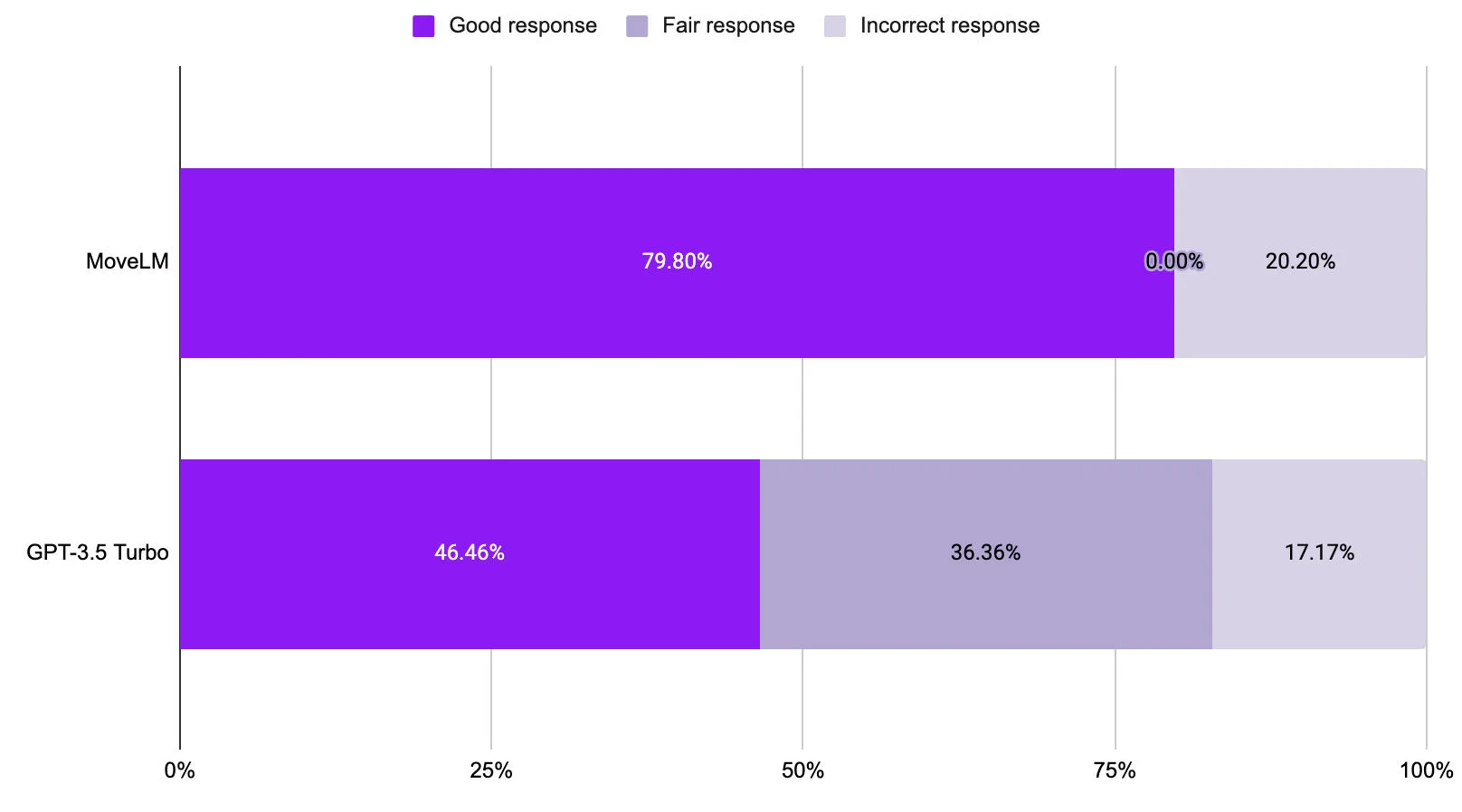 Figure 5: Evaluation results on the StrategyQA dataset comparing MoveLM and GPT-3.5 Turbo on reasoning, question answering, and summarization tasks. MoveLM consistently outperformed GPT-3.5 Turbo.
Figure 5: Evaluation results on the StrategyQA dataset comparing MoveLM and GPT-3.5 Turbo on reasoning, question answering, and summarization tasks. MoveLM consistently outperformed GPT-3.5 Turbo.
To evaluate generalizable intelligence beyond enterprise tasks, MoveLM and GPT Turbo were tested on the held-out StrategyQA dataset. This external dataset, cleaned up by our annotators, tests a model's ability to reason, answer questions, and summarize information. The results show that MoveLM achieves state-of-the-art performance even on tasks outside of its specialized enterprise training. This result demonstrates the versatility of MoveLM beyond narrow enterprise applications.
Proactive risk management throughout MoveLM's development
While developing MoveLM, we made responsible AI practices a priority at each stage.
Our first line of defense was developing a diverse corpus of proprietary data. By leveraging high-quality task-specific data and avoiding web-scraped sources, Moveworks mitigates risks like ingesting harmful content. We applied careful data preprocessing, using techniques like data masking, differential privacy, semantic deduplication, and mixture control to reduce potential harm.
During training, we closed each phase to minimize stability issues. We also proactively engaged external researchers to assess potential model impacts across dimensions like fairness and misuse.
Our evaluation framework was meticulously designed to enable granular testing of model behavior using customized real-world examples. This approach allowed us to identify undesirable edge case responses for further tuning.
Our cross-functional team worked diligently to enact responsible development practices throughout MoveLM’s creation. We remain committed to this level of care as deployment plans commence. By prioritizing ethical AI and risk management at each step, we strive to develop models that businesses can trust and adopt safely. We welcome additional collaborations to strengthen our approach.
MoveLM is AI built for the workplace
MoveLM represents a new paradigm in enterprise AI — where specialized deep learning models forged with in-house data and expertise unlock unprecedented productivity.
By curating high-quality proprietary data and generating targeted supplementary examples, we overcame the "bigger is better" notion that quantity surpasses quality. MoveLM provides a blueprint for smaller, more capable models with the right data and training for specific tasks.
Most importantly, MoveLM's real-world fluency tackles challenges pervasive models still struggle with daily. Our rigorous evaluation validates MoveLM's readiness to excel at nuanced enterprise tasks and take on work alongside human teams.
With customizable models like MoveLM achieving advanced reasoning skills tailored for targeted needs, the future possibilities for AI business applications are boundless. MoveLM paves the way for performant and trustworthy AI assistants that users can count on as truly capable colleagues. We are thrilled to unlock the next stage in that journey.
We would like to thank the individuals listed below for their invaluable feedback:
Jayadev Bhaskaran, Machine Learning Engineer
Cody Kala, Software Engineer
Aaksha Meghawat, Machine Learning Engineer
Matthew Mistele, Tech Lead Manager, NLU
Tianwei She, Machine Learning Engineer
Learn how Moveworks' LLM stack drives ROI, reduces busy work, and improves employee experience.


