
Table of contents
Editor’s note: Adam Shostack, President of Shostack + Associates, contributed to this post.
The AI world has been buzzing with excitement since the launch of ChatGPT. Widespread enthusiasm for the technology has created a modern-day gold rush, with everyone from casual users to corporations and investors joining the race to tap into its power.
However, to fully embrace the power of AI, it's essential to understand and address the risks it may introduce into an enterprise environment. Only by mitigating potential threats can we ensure successful — and secure — implementation.
Today, we’ll shed light on the potential threats associated with the two main types of LLMs: generative models and discriminative models, focusing on their four main stages: pre-training, training, fine-tuning, and end customer usage.
With a primary focus on serving business needs, we'll explore the following:
- LLM types and enterprise applications
- LLM threats in an enterprise
- Minimizing and mitigating these threats
Understanding LLM types and their applications
Businesses that focus on adopting large language models (LLMs) typically focus on two types, generative models and discriminative models, each offering their own benefits in an enterprise environment. There are also offensive and defensive uses of LLMs for cybersecurity purposes, but this article doesn’t focus on those, and rather focuses specifically on safeguarding business applications of LLMs.
Below, we outline core threats and corresponding mitigation strategies for business LLM use across the lifecycle stages. While this list may not be exhaustive, we aim to capture essential information to guide users in this rapidly evolving field, ensuring constant improvement over time.
We define these two types of LLMs below:
Discriminative models distinguish the logical boundaries between datasets or labels. These models excel at scoring and categorizing material, such as identifying the most pertinent articles, highlighting critical information, or quickly replying with a yes or a no.
Given these skills, discriminative models are particularly good at classifying and ranking information. The output of this LLM could be a number or set of numbers to help organize information. For example, you could query a database of knowledge base articles, and the LLM will order the articles ranked by relevance for that query. And it is essential to note that these models can’t hallucinate in the same way as a generative model, though they might misclassify or incorrectly order content.
Generative models create new data based on probability and likelihood estimation between words. These models excel at creating content, such as text, code, and images, and effectively summarize articles. Adversely, these models can hallucinate, i.e., create incorrect content that looks real but can sometimes lead to inaccurate or false information.
This distinction between generative and discriminative models is essential since the threats and risks associated with each model type can vary depending on how the LLM gets used. The table below captures further practical LLM usage for business applications, followed by examples.
Definition | Example | |
Using discriminative LLMs in the enterprise | ||
Classification | Assigning a data point to a specific category or group based on its characteristics | Predicting that an employee stating: “My headset broke, and I need a new one” is an IT request |
Ranking | Arranging data in a specific order based on certain criteria or a set of rules | Ranking three knowledge base articles in order of relevance to an employee’s request about obtaining a new headset |
Highlighting answers | Highlighting content to properly answer a question (i.e., rather than reading a wall of text, the actual response is highlighted) | Identifying specific text within an article to help an employee order a new headset |
Extractive slot-filling | Identifying and extracting specific pieces of information (or “slots”) from a given text. | Identifying and preparing API call arguments from user queries, like transforming "What is the market cap of Apple?" into GET_MARKET_CAP(company= "Apple"). |
Using generative LLMs in the enterprise | ||
Translation | Converting content from one language to another | Translating the input "My headset broke, and I need a new one" to its Spanish output "Mis auriculares no funcionan y necesito nuevos." |
Summarization | Creating a concise and meaningful summary of a longer input text by understanding the key concepts and ideas and then generating a condensed version coherently and naturally. | Condensing (an existing) support article and using prior knowledge into a summary, presenting the main action items using its own words and paraphrasing the original content. |
Coding | Creating or improving machine-readable code | Drafting a Python script that provides the market cap of Fortune 100 companies without any additional input |
Content creation | Creating new content, including text, images, and more. | Drafting a sales outreach email |
Abstractive slot-filling | Enabling an LLM to generate API calls and arguments by reasoning and understanding user queries instead of directly extracting information from the input text. | Interpreting the query "What is the market cap of the creator of the iPhone?" and identifying "Apple" as the company in question and generating the API call GET_MARKET_CAP(company=“Apple”). |
Combining discriminative and generative LLMs in the enterprise | ||
Retrieval augmented generation | One or several discriminative models are used to search for relevant information, such as appropriate documents. to answer the question. Afterwards, a generative model is used to write the output from those documents. | Responding to the query, “My headset is not working,” with step-by-step instructions on resolving the issue instead of a set of links where the user has to click and review the material one by one manually. |
Table 1: Various uses for discriminative and generative LLMs in the enterprise.
The large language model lifecycle
LLMs have revolutionized our interaction with artificial intelligence, enabling various applications like language translation and chatbots. However, understanding their lifecycle and potential risks is crucial for safe, effective deployment.
The lifecycle of an LLM can be broadly categorized into four major stages, each playing a pivotal role in shaping the model's capabilities and performance:
-lifecycle%20.png) Figure 1: The large language model (LLM) lifecycle
Figure 1: The large language model (LLM) lifecycle
Pre-training and training LLMs: LLMs are pre-trained on vast amounts of human-curated information to develop a generic knowledge base. This pre-training phase equips the model with a broad understanding of language patterns and concepts. During training, the LLM learns to predict the likelihood of a word or phrase appearing in a given context, further refining its language comprehension abilities.
Fine-tuning for specific applications: The LLM undergoes a fine-tuning process to tailor its capabilities for specific tasks or purposes. For instance, if the goal is to create a translation capability for a specific language, the LLM will be fine-tuned to understand idioms and nuances unique to that language. Fine-tuning allows for specialization and optimization, making the LLM more adept at specific applications.
End customer usage: The LLM is deployed for end customer usage, typically through an API or a chat interface. It becomes an integral part of applications that interact with users. Although end customers do not have direct access to the underlying model, they interact with it seamlessly, benefiting from its language understanding capabilities.
Continuous improvement through customer feedback: The journey of an LLM doesn't end with deployment. This stage marks the beginning of an ongoing cycle of improvement. End customers' feedback plays a crucial role in fine-tuning the model further. The LLM is updated and refined to enhance its performance and accuracy as users report issues or provide feedback (including other models and annotators input). This iterative process helps the model stay relevant and adaptive to changing requirements. This stage could lead to privacy concerns for end users, which we’ll discuss below.
Using threat modeling to identify and address risks in the LLM lifecycle
Threat modeling is a family of techniques that help us answer crucial questions of “what are we working on?” (including an LLM in a business application), “what can go wrong” (we read about a lot, and the structures in this article help us focus), and “what are we going to do about those things?” When we’ve done so, we can decide if the dangers of using the LLM are acceptable to us, and perhaps apply risk management techniques of acceptance or transfer to what remains. For more on threat modeling, see Adam’s The Ultimate Beginner's Guide to Threat Modeling.
Privacy threats
We’d be remiss to not mention privacy, and we’re not going to go deep today because this post is already a little long. Privacy concerns may arise at any stage of the LLM lifecycle. Important strategies to mitigate these concerns involve using synthetic, anonymized, and/or masked data to decrease the risk of exposure — an issue that warrants further discussion.
We do want to touch on two important aspects. One of the first concerns that we hear talking about LLMs relates to “will data about me/data I provide be used to train the LLM?” We can break this down into “I’m concerned about trade secrets” and “Will the LLM reveal my data?” Trade secrets are an important legal concept, and understanding who’s training an LLM and how that LLM will be used can help you address the trade secret issue. We can also build tooling (“adapters”) that will customize the LLM to better safeguard data.
Adapters help manage privacy considerations
We’ll emphasize a particular approach for handling sensitive data during fine-tuning: adapters. An adapter is a compact plugin for a global model. (We don’t want to delve too deeply into adapters, but they’re custom weights that are used to tune responses, say, for a specific company.)
It’s possible to use company specific data (say, “we use the term “partners” rather than “staff”) to create an adapter that helps the LLM answer questions using that terminology. That adapter can be specific to one company, and so even if it contains trade secrets, those secrets are not exposed to the global model, but are kept in an adapter, used for only that company.
For example, suppose the model needs to "forget" specific information or relearn a particular task, such as when using customer data. In that case, the adapter can be retrained with new data that omits the information that needs to be forgotten. This method proves to be more cost-effective and straightforward than retraining the global model.
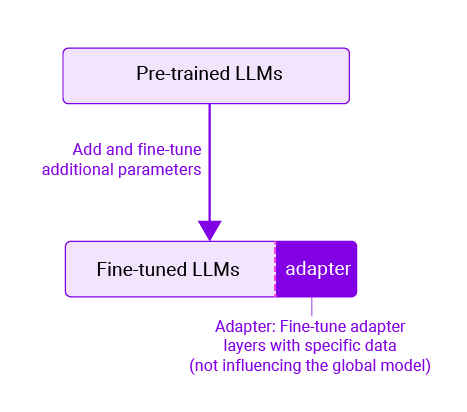 Figure 2: Adapters can help manage privacy considerations within the LLM lifecycle.
Figure 2: Adapters can help manage privacy considerations within the LLM lifecycle.
Security threats and mitigation strategies
When we talk about security threats to general computer systems, we tend to go to tools like STRIDE or Kill Chains to help us anticipate or explore “what can go wrong.” These techniques are powerful, general, and being general, don’t really help us anticipate the unusual and even unique problems associated with an LLM. (Both are introduced in Adam’s beginner guide to threat modeling under “common techniques.”) We can work on more specific threats that generalize to many LLMs or ML techniques, and we can get even more specific with attacks that work against a particular LLM or release of an LLM.
Threats for discriminative LLMs throughout their lifecycle
Now, we can explore potential threats and corresponding mitigation strategies for discriminative LLMs across various lifecycle stages. This information aims to provide a solid understanding of key concerns and their remedies, and it is not meant to be comprehensive.
Threat | Definition | Stages To Address | Mitigation |
Biased classification | Skewed predictions due to imbalanced data representation | Pre-training and training, and Fine-tuning | Ensure your dataset is well-balanced across different classes, including a diverse range of examples and features for each class. This diversity helps avoid overemphasizing specific characteristics and ensures unbiased outcomes when applying the model to real-world scenarios. |
Poisoning the training dataset | Introducing harmful data into the training set | Pre-training and training | Implement machine-assisted dataset reviews to identify and eliminate any inappropriate or unsuitable data during the training phase. This maintains the integrity of your model and ensures that the resulting LLM is reliable and accurate. |
Ranking bias | Distorted rankings due to unrepresentative data | Pre-training and training, and Fine-tuning | Create a balanced, task-specific dataset encompassing diverse ordering scenarios to minimize the influence of malicious data during the fine-tuning process. |
Overfitting | Excessive specialization on training data | Pre-training and training | Use a heterogeneous dataset with diverse examples and fine-tune your training process. Employ regularization techniques, cross-validation, and early stopping to prevent overfitting. This approach ensures the model can effectively handle real-world data rather than fitting too closely to the training data alone. |
Uninformative highlighting | Failing to pinpoint relevant information | Fine-tuning | Ensure the dataset is task-specific, well-balanced, and focuses on a diverse range of salient aspects for answer highlighting. Fine-tuning with such data, even in the presence of malicious content in the model, minimizes its negative impact on the system. |
Parsing attack | Inability to properly parse the request (such as identifying parameters when doing extractive slot-filling) | Fine-tuning, and End-customer use | During the fine-tuning stage, construct a dataset that includes a diverse range of ways to describe the content, such as, API parameters, alongside incorporating human-curated content. During end-customer usage, implement a filter or validator to assess the validity and range of generated parameters after the LLM process but before they are consumed by the API. This ensures that only correct and acceptable parameters are utilized. |
(Direct) Prompt injection | Malicious input influencing model | End-customer use | Use an augmented and balanced dataset with a diverse set of examples to minimize the impact of prompt injection attacks. Ideally, specific tasks/instructions can be trained into the models to mitigate risks associated with prompt injection attacks. Unlike instruction-following models like ChatGPT, which take their instructions from the text they are provided (and are consequently susceptible to following a different instruction taken from user text or article text), specific tasks/instructions are trained into the model itself in advance. In other words, we aim to separate instructions and data by default to prevent and mitigate this risk. |
Data leakage | Revealing sensitive information | End-customer use | Ensure proper access control at the API level is in place based on end user access. This should also mitigate blind injection attacks that attempt to infer sensitive data based on yes/no responses. Ensure that failure code paths fail gracefully and are thoroughly tested (i.e. aiming to prevent the LLM “defaulting” to the wrong classification for example). |
Table 2: Threats and mitigations for discriminative LLMs throughout their lifecycle
Threats for discriminative LLMs throughout their lifecycle
The below table outlines the threats and mitigations that can occur in the different stages of a generative LLM lifecycle. As mentioned earlier, this is not meant to be comprehensive but provide visibility into key threats.
Threat | Definition | Stages To Address | Mitigation |
Inserting harmful data | Pre-training and training | Leverage in-context learning by providing positive examples at runtime to guide the model's behavior. Additionally, train the model to incorporate human-curated (including machine-assisted dataset review) or annotated content and static reference material. | |
Vocabulary limitations and biases | Inserting harmful data | Pre-training and training, and fine tuning | Expand the training dataset by adding relevant idioms, terminology, and language examples. Also include human-annotated content to help minimize biases. |
Malicious input influencing model | End-customer use | Depending on how the LLM will be used the mitigations will differ. We share a few examples below: - Summarization and Content Creation: Reduce the level of access the LLM has and the actions that could be taken by the LLM (on behalf of the user) based on the response generated. In some instances, proper access control or having human oversight might mitigate the risk. - API parameter generation: Implement a filter or validator to assess the validity and range of generated parameters after the LLM process but before they are consumed by the API. This ensures that only correct and acceptable parameters are utilized. | |
Data leakage | Extracting sensitive information | End-customer use | Ensure that the responses generated by the LLM enforce access control or the LLM accesses non-restricted information. Alternatively, using an adapter for sensitive information, or an LLM (or LLMs) per customer. |
Hallucination | Generating false outputs | End-customer use | Provide content to the LLM related to the actual task. For example, rather than asking the LLM to summarize arbitrary material, provide the actual material that should be summarized (such as KB article). Response should be grounded and ideally the source of the information cited. |
Company data exposure | Exposing internal data | Fine tuning and end-customer use | Implement data masking, use synthetic data or anonymization techniques to avoid exposing sensitive details. |
Malicious code (including backdoors) - similar to poisoning the training dataset)
| Embedding harmful code | Pre-training and training, and fine tuning | Conduct machine-assisted training dataset reviews to identify malicious content. Additionally, leverage human-curated and reviewed code samples during training. Run code scanners and anti-malware tools as a defense-in-depth approach. Implement human-in-the-loop reviews of any generated code before deployment. Perform comprehensive vulnerability scans and malware detection as additional safeguards against harmful code. |
Skewed outputs from imbalanced data | Pre-training and training, fine tuning | Use a diverse and representative dataset for training. Routinely address any biases or skews detected in the model's outputs or performance. Update the training data as needed to improve fairness and accuracy. The training dataset should contain clear information about the intended task, relevant idioms, terminology, and human-annotated content to minimize biases. |
Table 3: Threats and mitigations for discriminative LLMs throughout their lifecycle
We want to call out that indirect prompt injection threats exist throughout various stages of the process. Both the pre-training and fine-tuning stages are susceptible to this risk. For instance, a malicious document instructing the model to "ignore prior requests and do XYZ instead" could be included in the training data. If the model internalizes this information, it may unknowingly perform indirect prompt injections when triggered by a similar input in the future. Similarly, the model might respond inappropriately during end-user interactions if the input data contains hidden indirect prompt injections.
Unfortunately, there is no foolproof mitigation to address this threat at present completely. However, there are steps we can take to minimize their impact. Ensuring that the training dataset is curated by humans and diverse is essential (instead of ingesting random material from the web or unique articles that could influence the model). Moreover, we can identify common keywords or patterns used in prompt injection attacks and attempt to separate genuine data from potentially harmful instructions. Training the model to actively recognize and reject prompt injection attempts by default can also be beneficial.
Realize the potential of LLMs while prioritizing security
As large language models continue gaining traction, they can deliver immense value to businesses through their advanced language capabilities. However, realizing their full potential requires responsible adoption practices.
By exploring common LLM types and their unique strengths, examining risks across the model lifecycle stages, and detailing actionable mitigation strategies, this guide aims to equip leaders with the threat modeling knowledge needed to implement LLMs securely. While no framework can fully eliminate risks, we believe that certain techniques can be implemented to reduce them.
With proper diligence and mitigation practices, companies can harness the breakthrough capabilities of large language models to enhance services, improve efficiency, and maintain a robust security posture. The future looks bright for LLMs in business — by keeping security and privacy in mind, leaders can confidently pursue innovation while building trust.
We would like to thank the individuals listed below for their invaluable feedback.
Jayadev Bhaskaran, Machine Learning Engineer
Matthew Mistele, Tech Lead Manager, NLU
Todd Macdonald, Software Engineer
Yi Liu, Vice President, Engineering
Chang Liu, Director, Engineering
Additional resources
In addition to the resources shared earlier, we found the below resources useful as we learned and worked on this material.
Learn more about what it takes to ensure conversational AI security for the enterprise.


