
In today’s fast-paced digital landscape, employee experience hinges on real-time connectivity and seamless efficiency. We recognize this critical need and are relentlessly pushing the boundaries of AI-powered employee services with our next-gen Copilot. However, keeping up with the latest and greatest large language models (LLMs) can present challenges, including latency.
Even the most sophisticated LLMs can succumb to processing delays, creating frustrating lags that disrupt conversational flow and hinder productivity. To overcome this hurdle, Moveworks is using NVIDIA’s TensorRT-LLM engine to achieve state-of-the-art optimizations for performant inference on LLMs.
The power of this adaptable engine is more than just theoretical. By leveraging its optimizations, we have significantly reduced LLM latency, paving the way for a new era of frictionless employee support. As you’ll see, the results speak for themselves.
In the following sections, we’ll dive deeper into:
- Why ultra-low latency matters to the Moveworks Copilot
- The benchmark results demonstrating TensorRT-LLM’s latency improvements
- How TensorRT-LLM optimizations work
- What the future holds for Moveworks’s collaboration with NVIDIA
Low latency matters for the Moveworks Copilot
The lag between user questions and AI responses, even a whisper of a delay, can shatter the magic of conversational AI. This challenge is why the pursuit of ultra-low latency is crucial to address. In particular, low latency unlocks two critical benefits for our Copilot, impacting both user experience and operational efficiency:
- Natural conversations: Every shaved millisecond translates to a smoother experience. Users remain engaged and unfazed by awkward pauses, and our Copilot evolves from a clunky robot to a trusted, responsive colleague.
- Maximum throughput, minimal cost: Lower latency empowers us to handle more concurrent conversations on existing infrastructure. This approach avoids costly horizontal scaling and optimizes resource utilization, maximizing throughput and minimizing cost.
This is where NVIDIA TensorRT-LLM helps us reduce lag with:
- Optimized kernels: Custom-built CUDA kernels make LLM operations exceptionally efficient, outperforming native Hugging Face models.
- Multi-GPU model parallelism: Tensor parallelism enables the distribution of an LLM over many GPUs while maintaining the low latency critical for production systems, allowing for more computing power to scale up state-of-the-art LLMs.
- Flexible Python API: A flexible approach allows for quick and easy customization of optimizations and seamless integration with existing LLM models.
With TensorRT-LLM, we’ve accelerated the Copilot user experience and optimized our operational efficiency. Given that background information, here are the benchmark test results showing the performance improvements from using TensorRT-LLM optimizations compared to not using those optimizations.
Comparing Copilot performance with and without TensorRT-LLM
The impact of TensorRT-LLM on Copilot’s performance goes beyond mere anecdotes. Let’s delve into the concrete data.
With TensorRT-LLM, our Copilot scales to handle over 2x tokens per second. Our benchmark tests demonstrate a jump from 19 tokens per second with standard implementations to a remarkable 44 tokens per second with TensorRT-LLM. The ability to handle more tokens per second speeds up model performance and empowers our developers to be more productive, efficient, and impactful in their work.
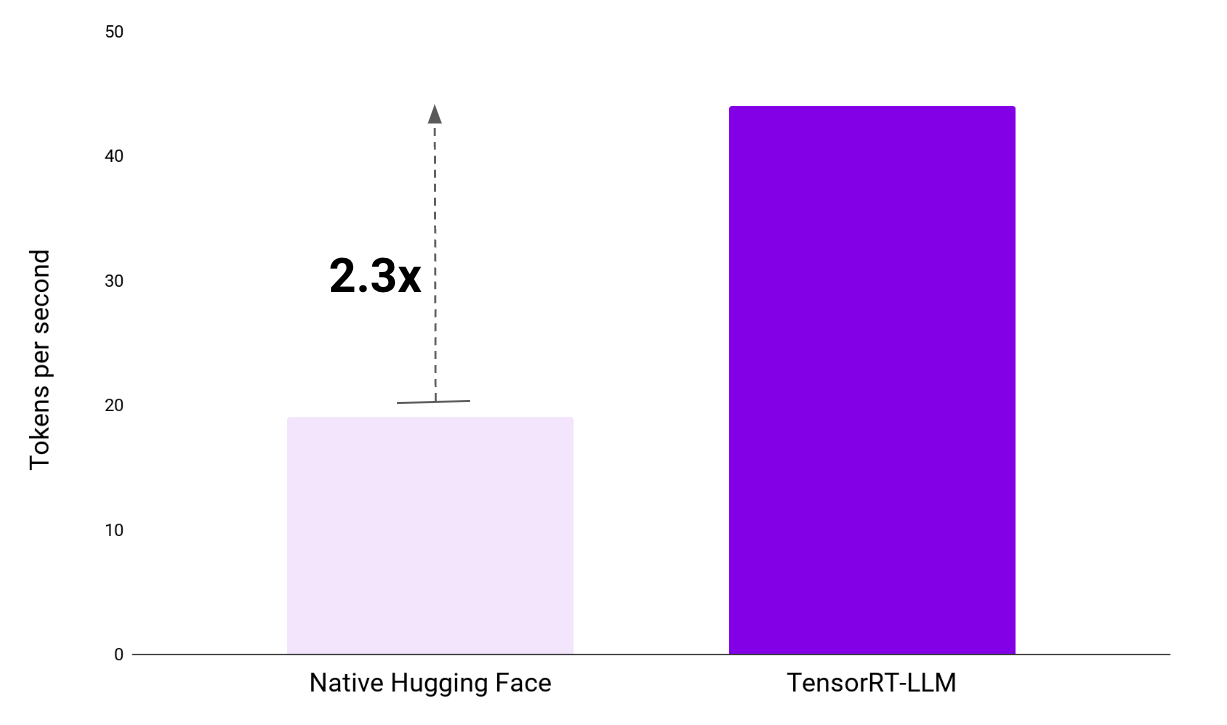 Figure 1: NVIDIA TensorRT-LLM doubles our Copilot’s token processing speed by 2.3x.
Figure 1: NVIDIA TensorRT-LLM doubles our Copilot’s token processing speed by 2.3x.
Similarly, response times underwent a dramatic transformation with TensorRT-LLM. In our testing, the average request latency shrunk by more than half, from a laggy 3.4 seconds to a crisp 1.5 seconds. TensorRT-LLM elevates the user experience by removing frustrating pauses, enabling smoother conversational flow, and increasing user engagement.
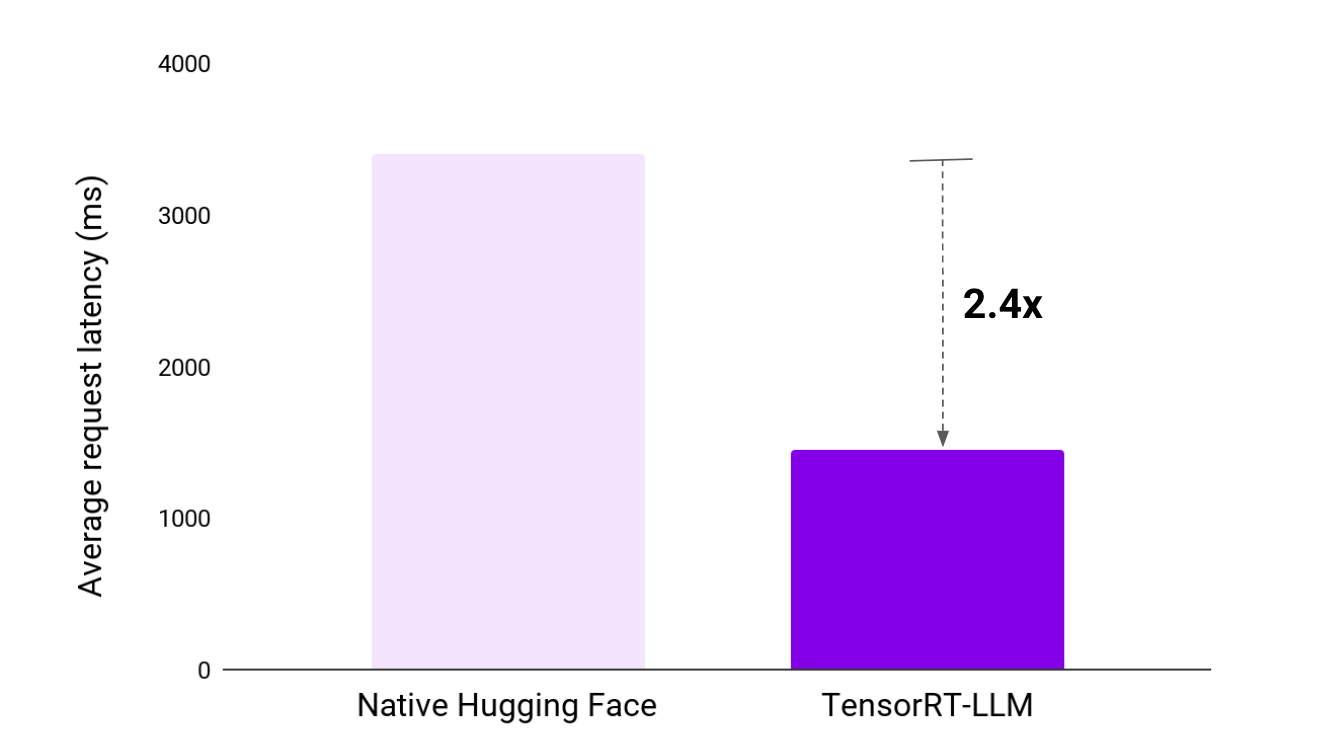 Figure 2: NVIDIA TensorRT-LLM cuts average response latency by over 50 percent.
Figure 2: NVIDIA TensorRT-LLM cuts average response latency by over 50 percent.
Finally, first token latency plays a crucial role in shaping perceived responsiveness. TensorRT-LLM excels in this area, reducing the first token latency from 0.8 seconds to a lightning-fast 0.3 seconds. This near-instantaneous initial feedback contributes significantly to the overall perceived latency of the end-to-end product.
To explain further, many LLM-driven applications stream output from the LLM to users one token at a time as the model generates the response. With a lower first token latency, users don’t have to wait for the entire response to be fully generated before seeing initial results. Instead, they experience a continuous flow of information in real time as the model produces each token. Reducing first token latency enables a more natural conversational experience where users receive continuous feedback instead of waiting for complete responses.
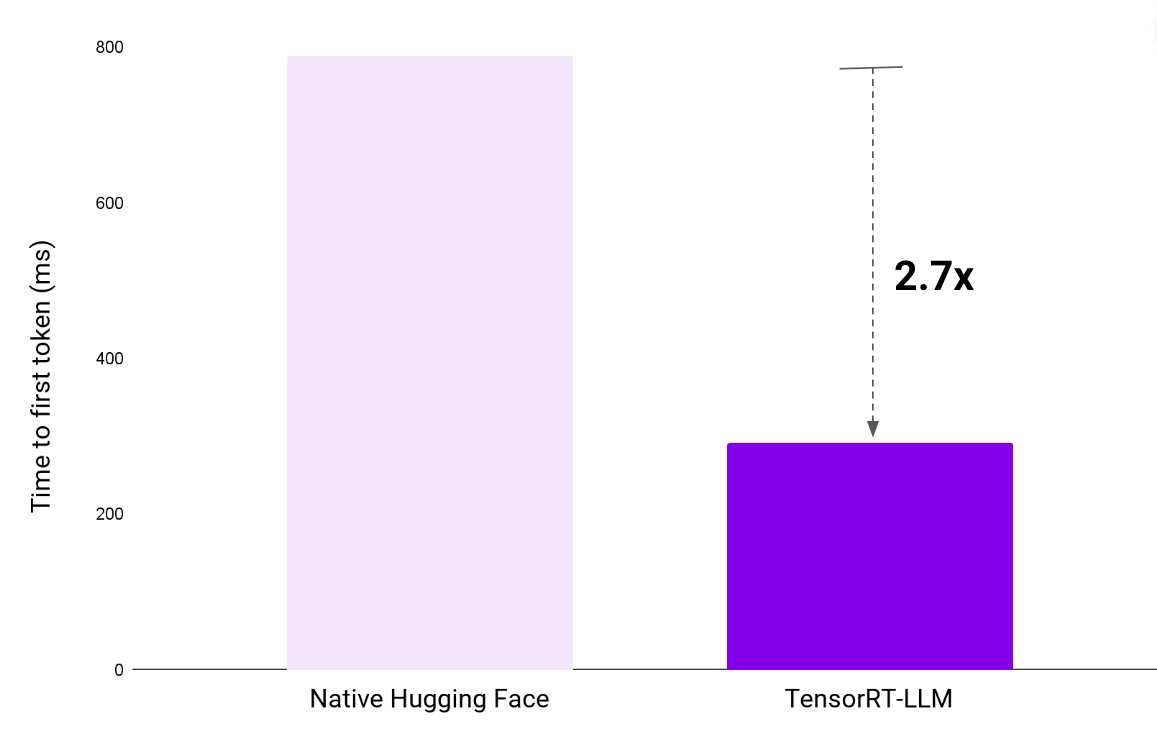 Figure 3: NVIDIA TensorRT-LLM produces a time to first token almost 3x faster than native Hugging Face models.
Figure 3: NVIDIA TensorRT-LLM produces a time to first token almost 3x faster than native Hugging Face models.
In real-world terms, these impressive benchmarks translate into tangible benefits for both employees and developers. Our Copilot, powered by NVIDIA TensorRT-LLM, can:
- Handle surges in demand with ease, delivering timely assistance for all employees without performance degradation.
- Enhance individual conversations by providing prompt and continuous responses, boosting user satisfaction and productivity.
- Optimize resource utilization by scaling on existing hardware, reducing infrastructure costs, and maximizing ROI.
Metric | NVIDIA TensorRT-LLM | Native Hugging Face | Improvement |
Tokens per second | 44 | 19 | 2.32x |
Average request latency (ms) | 1446 | 3401 | 2.35x |
Time to first token (ms) | 292 | 789 | 2.7x |
Figure 4: The Moveworks Copilot’s performance leaps forward with NVIDIA TensorRT-LLM optimizations.
With TensorRT-LLM, Copilot delivers a next-generation conversational experience for employees characterized by ultra-low lag, continuous engagement, and exceptional efficiency.
How NVIDIA TensorRT-LLM reduces latency
The Moveworks Copilot achieves lightning-fast response times by leveraging advanced optimizations from NVIDIA TensorRT-LLM. Key optimizations provided by TensorRT-LLM that help enable real-time conversational speed include:
- Multi-block mode with Flash-Decoding: This innovative technique fragments attention operations into smaller tasks, allowing parallel processing on GPUs. This slashes memory usage and processing time, especially for longer-form conversations.
- SmoothQuant: This optimization shrinks model size by converting weights and activations to a smaller format. The benefit? More compact models lead to quicker responses and happier users.
Beyond the headliners, TensorRT-LLM leverages a symphony of additional techniques, including:
- Int8_kv_cache: Stores intermediate results efficiently, maximizing memory usage.
- Use_gpt_attention_plugin: Tailors attention operations for optimal LLM performance on NVIDIA GPUs.
- Use_gemm_plugin: Speeds up critical matrix multiplication tasks.
These combined techniques help unlock Copilot’s remarkable performance so it can handle more conversations, respond more instantly, and deliver an ultra-low lag experience for every employee.
Beyond low latency, a future of frictionless work with Moveworks, powered by NVIDIA
The results shared above clearly demonstrate the powerful impact of NVIDIA TensorRT-LLM on the Moveworks Copilot. Powered by TensorRT-LLM, our Copilot is driving a future where:
- Latency is a relic: Conversations with AI flow seamlessly with instantaneous responses, eliminating frustration or lost momentum.
- Scalability meets efficiency: A single Copilot can handle surges in demand, effortlessly supporting hundreds of employees simultaneously.
- Resource optimization takes center stage: Optimized processing powered by TensorRT-LLM reduces infrastructure costs and maximizes ROI.
But this is just the beginning. Our collaboration with NVIDIA has opened the door to new possibilities in transforming employee support and productivity, helping us build a future where employees and AI can engage in seamless, real-time conversations.
In collaboration with NVIDIA, we are redefining the boundaries of what’s possible with large language models. The Moveworks Copilot is becoming a trusted, responsive digital colleague for employees, not just a helpful chatbot. The benefits extend across organizations — from maximizing everyday employee productivity to optimizing operational efficiency and infrastructure costs.
This blog has explored the technical optimizations powering our Copilot’s step change in performance. But the human impact goes much further. Join us at Moveworks.global 2024 as we showcase how AI-powered conversations are removing friction from work and unlocking the full potential of every employee.
Learn more about Moveworks’ AI, which powers the employee support copilot.
Table of contents


